
에이전틱 코드 리뷰 vs RAG: 멀티 리포지토리 분석에서 에이전트가 이기는 이유
해당 블로그는 Sahana Vijaya Prasad 원저자의 글 'Why agentic code review beats RAG for multi-repository analysis'을 번역한 것입니다. 더 나은 이해를 위해서 약간의 의역이 반영되었습니다.
오늘날의 소프트웨어 개발은 여러 리포지토리에 걸쳐 이루어집니다. 한 리포지토리의 변경(예: API 시그니처 수정)이 다른 여러 리포지토리의 소비자(consumer) 코드를 조용히 깨뜨릴 수 있죠. 그럼에도 대부분의 전통적인 코드 리뷰 도구는 각 PR을 고립된 단위로 취급하고, 리포지토리 경계를 넘는 이슈를 도구가 드러내주는 대신 리뷰어의 기존 시스템 지식에 기대고 있습니다.
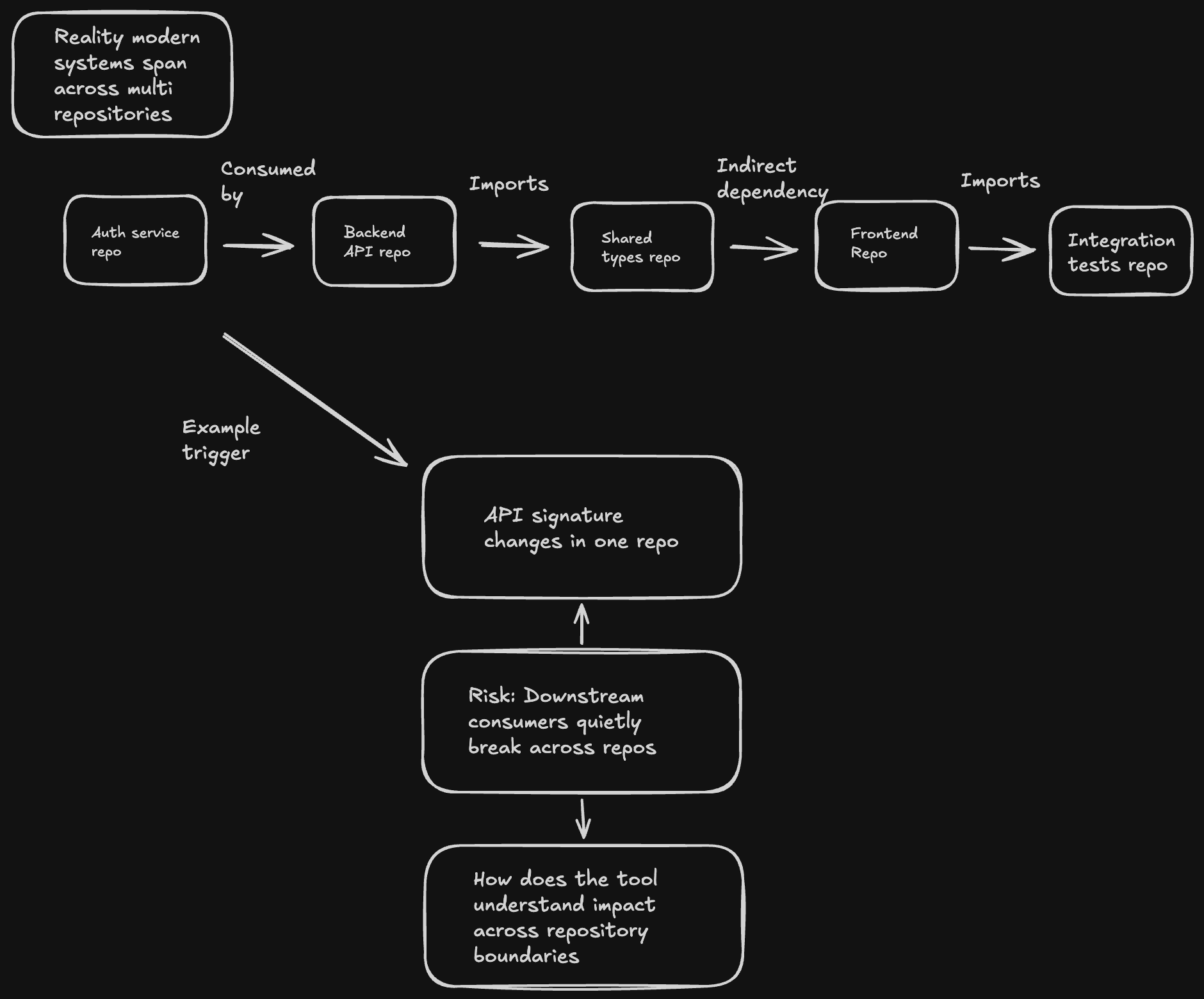 Figure 1: 현대 시스템은 여러 리포지토리에 걸쳐 있으며, 한쪽의 변경이 다른 쪽을 조용히 깨뜨릴 수 있습니다.
Figure 1: 현대 시스템은 여러 리포지토리에 걸쳐 있으며, 한쪽의 변경이 다른 쪽을 조용히 깨뜨릴 수 있습니다.
CodeRabbit은 2024년부터 에이전트를 만들어 왔습니다
CodeRabbit은 업계가 에이전트 기반 접근을 표준으로 받아들이기 전인 2024년부터 이미 에이전트 기반 검증(agent-based validation) 을 구현해 왔습니다. 그 과정에서 얻은 결론은 명확했습니다.
"리포지토리 경계를 넘는 코드 리뷰는 근본적으로 검색(retrieval) 문제가 아니라 조사(investigation) 문제다."
에이전트는 영향받는 호출 지점(call site)을 여러 리포지토리에서 찾아내고, 구체적인 파일 경로, 라인 번호, 심각도 수준까지 담긴 정밀한 검증 스크립트를 생성합니다. 예를 들어 UserService.createUser의 시그니처에 필수 파라미터 roleId가 추가된다면, 에이전트는 여러 리포지토리에서 이 변경으로 인해 실패가 발생할 정확한 위치들을 짚어냅니다.
대부분의 코드 리뷰 도구가 리포지토리 간 컨텍스트를 다루는 방식
지배적인 패턴은 RAG(Retrieval-Augmented Generation) 파이프라인 을 따릅니다.
- 인덱싱(Index): 관련 리포지토리의 코드를 청크로 나누고, 임베딩으로 변환한 뒤, 벡터 데이터베이스에 저장
- 검색(Retrieve): 변경된 코드도 같은 방식으로 변환하고, 최근접 이웃 검색(nearest-neighbor search)으로 수학적으로 유사한 청크를 반환
- 생성(Generate): AI가 검색된 청크와 PR 디프를 함께 받아 리뷰를 생성
겉보기엔 합리적이지만, 실전의 멀티 리포지토리 환경에서 이 방식은 여러 지점에서 무너집니다.
RAG 기반 코드 리뷰의 다섯 가지 한계
1. 검색 병목 (The retrieval bottleneck)
시맨틱 미스매치, 잘못된 청킹, 구조적 관계 누락 등의 이유로 초기 검색이 관련 코드를 놓치면, 복구 메커니즘이 없습니다. NVIDIA의 연구는 표준 RAG가 "한 번 검색하고 한 번 생성한다(retrieve once and generate once)"는 특성을 지니며, 첫 검색이 실패했을 때 폴백이 존재하지 않는다는 점을 지적합니다.
2. 일관성과 동기화 간극
현대 벡터 데이터베이스는 빠른 업데이트를 지원하지만, RAG 파이프라인은 여전히 여러 순차적 단계(변경 감지 → 재청킹 → 임베딩 재계산 → 인덱스 갱신)에 의존합니다. 멀티 리포지토리 환경에서는 이것이 복합적으로 악화됩니다. 새 소비자 리포지토리가 인덱싱되지 않았거나, 이름이 바뀐 심볼이 서로 충돌하는 임베딩을 가지고 있거나, 리포지토리 간 관계가 원자적으로(atomically) 갱신되지 않는 등의 문제가 쌓입니다.
3. 컨텍스트 오염 (Context poisoning)
의미적으로 유사하다고 검색된 정보가 실제로 관련성(relevance) 까지 보장하지는 않습니다. Anthropic 팀은 이를 "컨텍스트 부패(context rot)" 라고 명명한 바 있습니다. 코드 리뷰 맥락에서 이는 잘못된 코드를 근거로 한 그럴듯한 분석을 만들어내는데, 이는 분석이 아예 없는 경우보다도 오히려 나쁩니다.
4. 참조를 따라가지 못함
코드 관계는 본질적으로 구조적입니다. 함수 호출, import 문, 스키마 참조 모두 그래프 관계에 해당하며, 유사도 검색이 포착하기 어려운 형태입니다. 공유 타입 정의를 수정한 코드를 찾으려면 텍스트 유사도가 아니라 구조적인 import 관계를 식별해야 합니다.
5. 추론은 없고, 매칭만 존재함
벡터 검색은 텍스트적으로 유사한 코드를 찾을 수는 있지만, "인자 2개로 호출하는 지점이, 시그니처가 3개를 요구하기 때문에 실패한다"는 사실을 판단하지는 못합니다. 이를 위해서는 실제 코드를 읽고, 호출 지점을 이해하고, 불일치에 대해 추론할 수 있어야 합니다.
업계가 에이전틱 시스템으로 이동하는 이유
업계 리더들이 일제히 에이전틱 아키텍처로 수렴하고 있습니다.
- Anthropic의 "Building Effective Agents" 가이드는 리포지토리 간 영향 분석을 두고, "필요한 단계의 수를 미리 예측하는 것이 어렵거나 불가능하기 때문에" 에이전트가 필요한 시나리오라고 명시했습니다.
- OpenAI는 2025년 3월 Agents SDK를 공개하며, "단계별 프롬프팅에서 에이전트에게 작업을 위임(delegation)하는 방향으로 전환되는 시나리오"를 겨냥했습니다.
- Google Cloud는 이렇게 언급했습니다. "그라운딩(grounding)의 가장 강력한 접근은 에이전틱 RAG(Agentic RAG) 이며, 이때 에이전트는 더 이상 정보를 수동적으로 받는 존재가 아니라 능동적으로 추론에 참여하는 주체가 된다."
CodeRabbit의 접근: 에이전틱, 실시간 탐색
CodeRabbit은 코드를 정적인 표현으로 미리 인덱싱해 두는 대신, 연결된 리포지토리들을 실시간으로 탐색하는 자율 조사 에이전트(autonomous research agent) 를 운영합니다.
동작 방식
팀은 설정을 통해 관련 리포지토리를 선언합니다.
knowledge_base:
linked_repositories:
- repository: "org/backend-api"
instructions: "공유 타입을 소비하는 REST API 리포지토리"
- repository: "org/integration-tests"
instructions: "엔드투엔드 테스트 픽스처"
PR이 열리면, 에이전트는 다음과 같은 다단계 조사 전략을 실행합니다.
- PR 컨텍스트를 읽고, 무엇이 변경되었고 어떤 API, 인터페이스, 타입, 의존성이 영향을 받는지 파악
- 미리 계산된 아키텍처 요약(architectural summary) 을 활용해 영향받을 가능성이 있는 연결 리포지토리를 식별
- 해당 리포지토리들을 온디맨드로 격리된 샌드박스 환경에 클론해 실시간으로 탐색
- 결과를 되돌아보며(reflect) 탐색 전략을 조정. 처음 검색이 비어 있으면 대체 타입 이름, import 경로, 의존성 선언 등을 다시 시도
- 파일 경로와 라인 번호까지 포함해, 리뷰에 직접 관련된 발견 사항을 요약
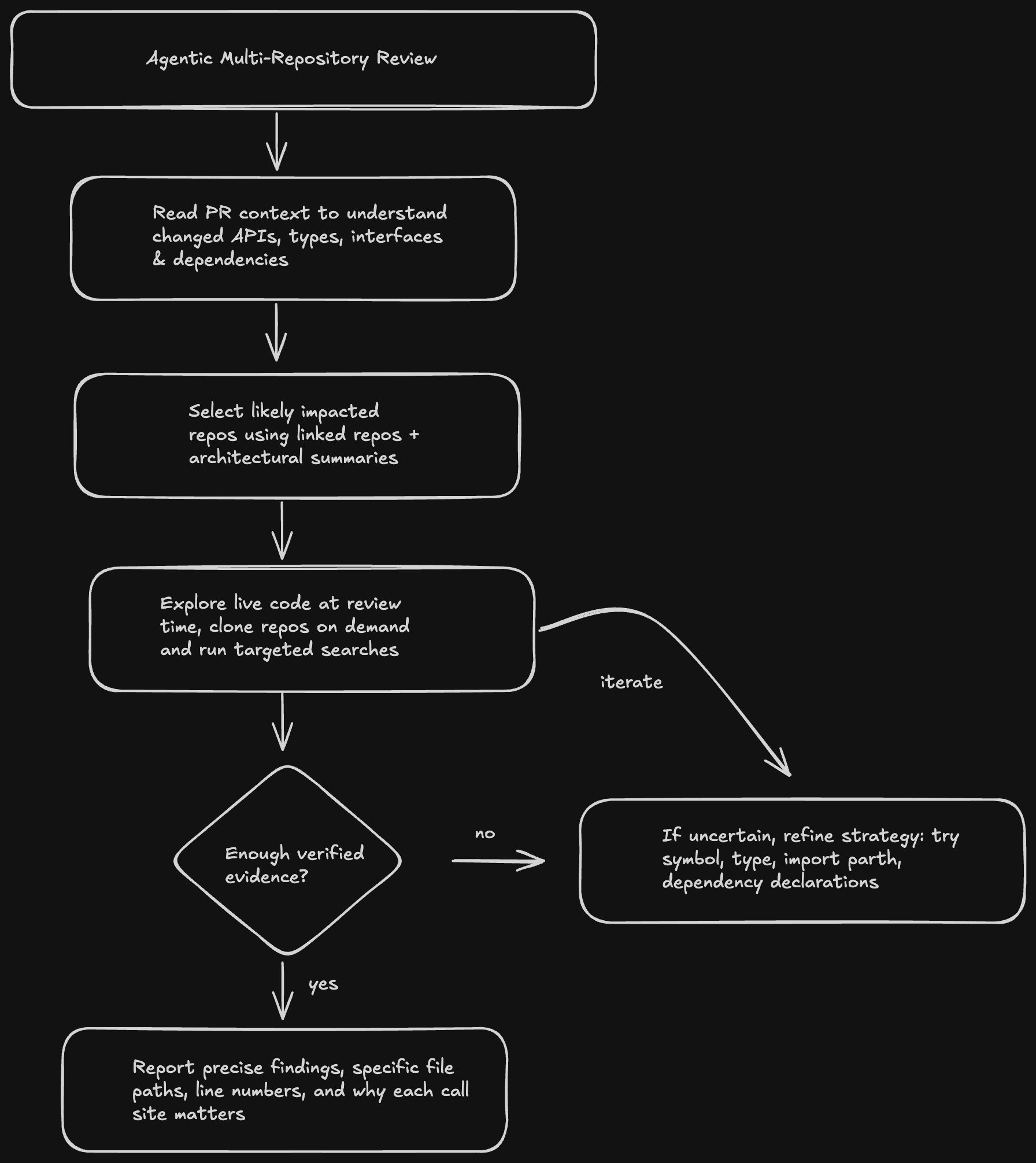 Figure 2: CodeRabbit의 에이전틱 리뷰 흐름. 검증된 근거를 확보할 때까지 반복(iterate)합니다.
Figure 2: CodeRabbit의 에이전틱 리뷰 흐름. 검증된 근거를 확보할 때까지 반복(iterate)합니다.
에이전트가 찾아내는 것, RAG가 찾지 못하는 것
에이전틱 접근은 구체적인 근거와 함께 깨지게 될 호출 지점을 식별합니다.
backend-api (org/backend-api)
src/controllers/admin.ts:45:createUser(email, name)을roleId없이 호출. 깨집니다.src/controllers/onboarding.ts:112: 스프레드 객체로createUser를 호출. 업데이트 필요 가능성 있음.
integration-tests (org/integration-tests)
tests/fixtures/user-factory.ts:23: 옛 시그니처로 사용자를 생성. CI에서 실패합니다.
차이는 구조적입니다. "유사한 코드 청크 목록"을 제시하는 단계에서, "파일 경로와 라인 번호까지 특정된, 실제로 깨질 세 개의 호출 지점"을 제시하는 단계로 넘어가는 것이죠.
정면 비교: 에이전틱 vs RAG 기반 멀티 리포지토리 리뷰
| 기준 | RAG 기반 리뷰 도구 | CodeRabbit (에이전틱) |
|---|---|---|
| 데이터 신선도 | 마지막 인덱스 빌드 시점 반영 (수 시간~수일 지연) | 항상 HEAD 기준 라이브 코드 |
| 누락된 결과로부터의 복구 | 없음. 단일 샷(one-shot) 검색, 폴백 없음 | 에이전트가 반복: 대체 검색, 참조 추적, 파일 직접 확인 |
| 코드 관계 이해 | 텍스트 유사도만 사용. import, 콜 그래프, 타입 계층 추적 불가 | 구조적으로 탐색: import grep, 호출 지점 열람, 타입 정의 추적 |
| 영향 추론 | 유사 청크 반환. 실제로 깨질지 여부 판단 불가 | 코드를 읽고 인자 수/타입 호환성 확인, 실제 영향 추론 |
| 모호성 처리 | 신뢰도와 무관하게 top-k 반환 | 결과 품질을 반추, 불확실 시 정교한 재검색 후 자체 판단으로 종료 |
| 발견 사항의 정밀도 | 코드 청크 (대체로 부분적, 때로는 무관한 것) | 구체적 파일/라인, 왜 문제인지에 대한 설명 포함 |
| 보안 모델 | 외부 서비스에 코드의 영속 인덱스 필요 | 격리된 샌드박스로 온디맨드 클론. 코드 영속 저장 없음 |
엔지니어링 리더에게 이것이 의미하는 바
주요 업계 플레이어들(Anthropic, OpenAI, Google, Microsoft)이 에이전틱 인프라(MCP, Agents SDK, Agent Development Kit, A2A Protocol)에 투자하고 있다는 사실은, 자율 추론 시스템이 정적 검색 파이프라인을 대체할 것이라는 분명한 신호입니다.
리포지토리 간 코드 리뷰에는 다음이 요구됩니다.
- 오픈엔디드 탐색: 어떤 파일이 중요한지를 도구가 사전에 알 수 없음
- 구조적 이해: 중요한 관계는 텍스트 유사도가 아니라 import, 호출 지점, 타입 계층
- 불확실성 하에서의 추론: 어떤 변경이 소비자를 깨뜨릴지를 도구가 판단할 수 있어야 함
- 실시간 정확성: 오래된 결과는 잘못된 자신감을 낳으며, 차라리 결과가 없는 것보다 더 나쁨
RAG는 멀티 리포지토리 코드 리뷰에 근본적으로 맞지 않는 도구입니다. 질의응답 형태로 LLM을 지식 베이스에 그라운딩하는 데에는 탁월하지만, 리포지토리들을 넘나드는 코드를 분석하는 일은 단순한 지식 검색이 아니라 조사적 추론(investigative reasoning) 을 요구합니다.
CodeRabbit이 에이전틱 아키텍처를 선택한 이유는 단순합니다. "그것만이 실제로 이 문제를 푸는 아키텍처이기 때문" 입니다. 그리고 업계는 이제, CodeRabbit이 2024년부터 구현해 온 그 방향으로 수렴하고 있습니다. 실제 멀티 레포 환경에서 AI 코드 리뷰가 어떻게 작동하는지 더 보고 싶으시다면 CodeRabbit 멀티 레포 분석 사례를, 에이전트가 IDE를 넘어 협업 표면 어디로 확장될지는 이제 IDE는 소프트웨어 개발의 중심이 아닙니다를 함께 보시는 것을 추천 드립니다.