
Claude Fable 5 모델 리뷰: 코드 리뷰와 코딩 작업 초기 신호
해당 블로그는 Juan Pablo Flores, Gowtham Kishore Vijay 원저자의 글 'Fable 5 model review: Early signals from code review and coding tasks'을 번역한 것입니다. 더 나은 이해를 위해서 약간의 의역이 반영되었습니다.
Fable 5는 자율 코딩 작업에서 한 번쯤 테스트해 볼 만한 모델입니다. 특히 프롬프트가 불완전해서 에이전트가 무언가를 만들기 전에 먼저 환경을 파악해야 하는 상황에서 빛을 발합니다. 다만 프로덕션 코드 리뷰라면 현재 베이스라인과 Opus 4.8이 여전히 더 안전한 선택으로 보입니다.
Fable 5는 작업이 충분히 명세되지 않았을 때 에이전트의 체감을 바꿔 놓는 부류의 모델입니다. 탐색을 잘 이끌어 가거든요. 먼저 환경을 학습하고 어떤 파일과 도구, 제약이 주어졌는지 파악한 다음 그렇게 다져진 그림 위에서 작업을 시작합니다. 무엇을 하려는지 길게 늘어놓는 데 시간을 쓰지 않습니다. 컨텍스트가 충분하면 곧장 만들기 시작합니다.
모델의 역량을 테스트하려고 진행한 여러 코딩 프로젝트에서 이런 모습을 확인했습니다. Fable 5에 모호한 프롬프트를 줘도 프로토타입 껍데기가 아니라 완성된 프로젝트가 돌아왔습니다. 손을 더 잡아 주지 않으면 기존 모델 리뷰들이 도달하기 어려웠던, 덜 뻔한 해법 경로까지 찾아내기도 했죠.
같은 특성이 비용으로도 드러납니다. 저희 코딩 작업 벤치마크에서 Fable 5는 하니스(harness)가 중단시킬 때까지 작업을 이어 가는 경우가 잦았습니다. 덕분에 모델이 유능하게 느껴지지만 동시에 비싸고 느려지기도 합니다. 강한 정지 규칙이 없는 에이전트 워크플로에서는 특히 그렇습니다.
그래서 권장 사항이 "전부 다 바꾸세요" 같은 깔끔한 결론은 아닙니다. 자율성 자체가 결과물인 영역에서는 Fable 5를 쓰고 정밀도와 코멘트 양이 다듬어지는 동안에는 현재 코드 리뷰 경로를 유지하는 쪽입니다.
한 문단으로 보는 결정
탐색하고 계획하고 만들어 내는 일이 과제일 때 Fable 5를 쓰세요. 더 꼼꼼한 구현을 얻는 대가로 작업이 더 오래 걸려도 괜찮은 경우라면 더욱 그렇습니다. 코드 리뷰는 지금으로서는 현재 리뷰어를 그대로 유지하시는 편이 좋습니다. 코드 리뷰 신호는 커버리지에서는 근접했지만 기본값으로 삼기에는 정밀도나 코멘트 양이 아직 충분히 강하지 않습니다.
Fable 5의 새로운 점
Fable 5는 자율적인 지식 노동과 코딩을 위한 Mythos 등급 모델로 자리매김했습니다. 일상적인 모델 업그레이드와는 기준선 자체가 다르다는 뜻이죠. 약속하는 것은 단순히 더 나은 답변이나 더 빠른 Opus 4.8이 아닙니다. 더 오래 돌아가는 에이전트 작업을 위해 설계된 모델입니다. 더 많은 컨텍스트를 유지하고 계획을 세우며 사람이 개입해야 하는 시점까지 작업을 더 멀리 끌고 갑니다.
출시 단계의 제약도 역량 측면에서 여전히 중요합니다. 이 모델은 일부 사이버보안 및 생물학 요청에 대해 차단 분류기(blocking classifier)를 탑재하고 있으며 분류기가 차단한 뒤에는 옵트인 방식으로 Opus 4.8로 폴백하는 기능을 지원합니다. 개발자 입장에서 실무적인 결론은 단순합니다. 깊이가 필요한 작업에는 Fable 5를 쓰고 예측 가능한 속도나 정밀도가 필요한 워크플로에는 기존 경로를 유지하세요.
릴리스 브리프에 적힌 공개 출시 가격은 입력 100만 토큰당 $10, 출력 100만 토큰당 $50이며 리전 엔드포인트에는 10% 할증이 붙습니다. 추론 모델, 특히 새로운 모델 카테고리를 도입하는 경우 이 정도 가격은 전에도 본 적이 있습니다. 이런 비용은 이후 버전을 거치며 내려갈 수 있겠지만 초기 그림만큼은 분명합니다. 개발자는 Fable 5를 토큰 단가가 아니라 해결한 작업당 비용(cost per solved task)으로 평가해야 합니다.
코드 리뷰: 커버리지는 근접, 정밀도는 약함
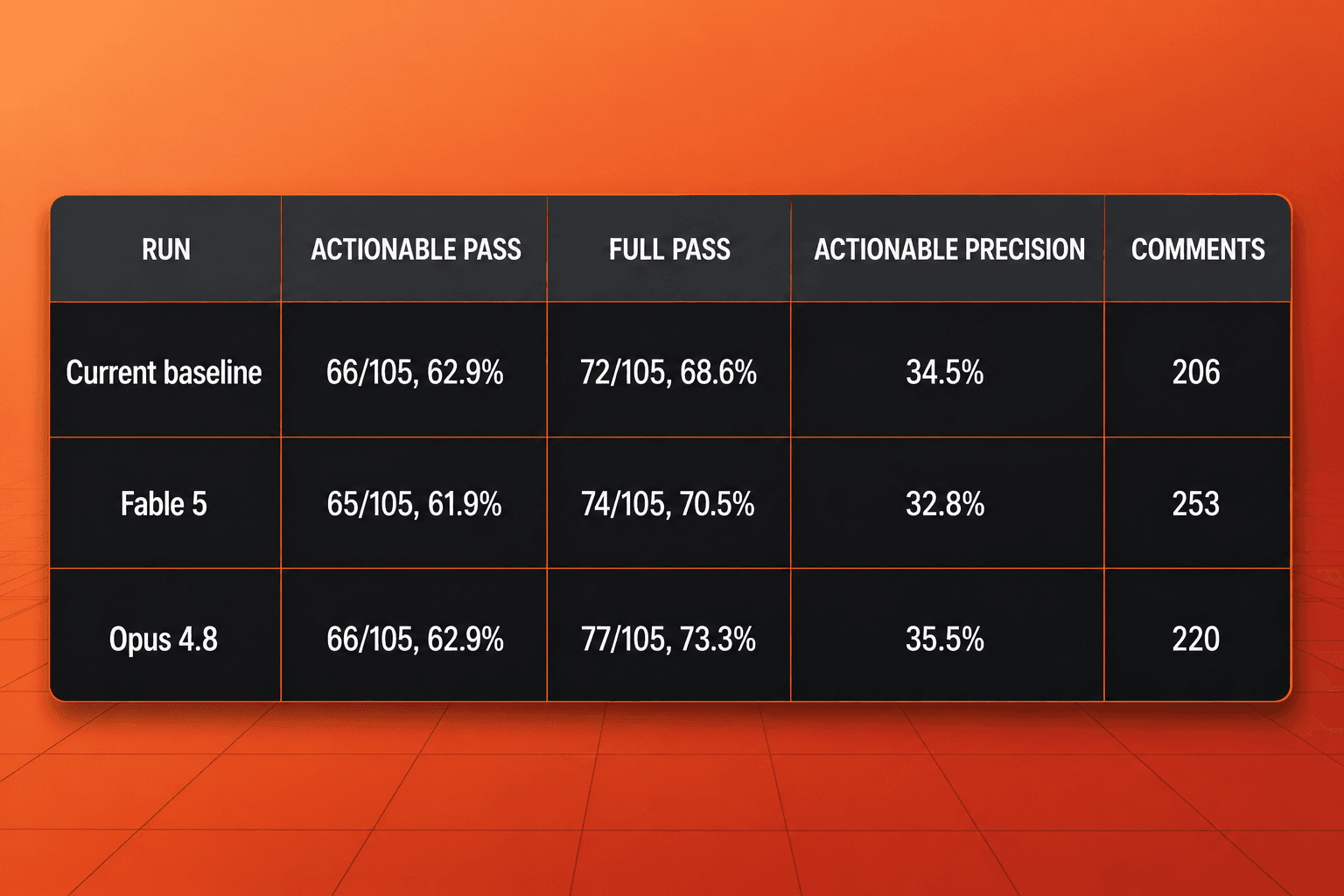
105개 EP 코드 리뷰 벤치마크에서 Fable 5는 발견 커버리지 면에서 현재 베이스라인에 바짝 붙었습니다. 실행 가능한(actionable) 105개 EP 중 65개를 통과했는데 베이스라인과 Opus 4.8의 66개에 살짝 못 미치는 수치입니다. 모든 코멘트 유형을 합산하면 Fable 5가 베이스라인을 근소하게 앞섰습니다. 전체 EP 통과 기준으로 105개 중 74개를 통과해 베이스라인의 72개를 넘었습니다.
약한 쪽은 정밀도입니다. Fable 5는 실행 가능 정밀도 32.8%, 전체 정밀도 19.4%에 그쳤습니다. Opus 4.8은 각각 35.5%와 26.5%에 도달했습니다. 또한 Fable 5는 253개의 코멘트를 생성해 두 비교 대상보다 많았고 단정적(assertive)이고 nitpick 성격의 출력이 크게 늘었습니다. 이 조합은 코드 리뷰에서 중요한 의미를 갖습니다. 커버리지가 경쟁력 있어 보이더라도 잡음 섞인 코멘트는 리뷰어의 일거리를 늘리기 때문입니다.
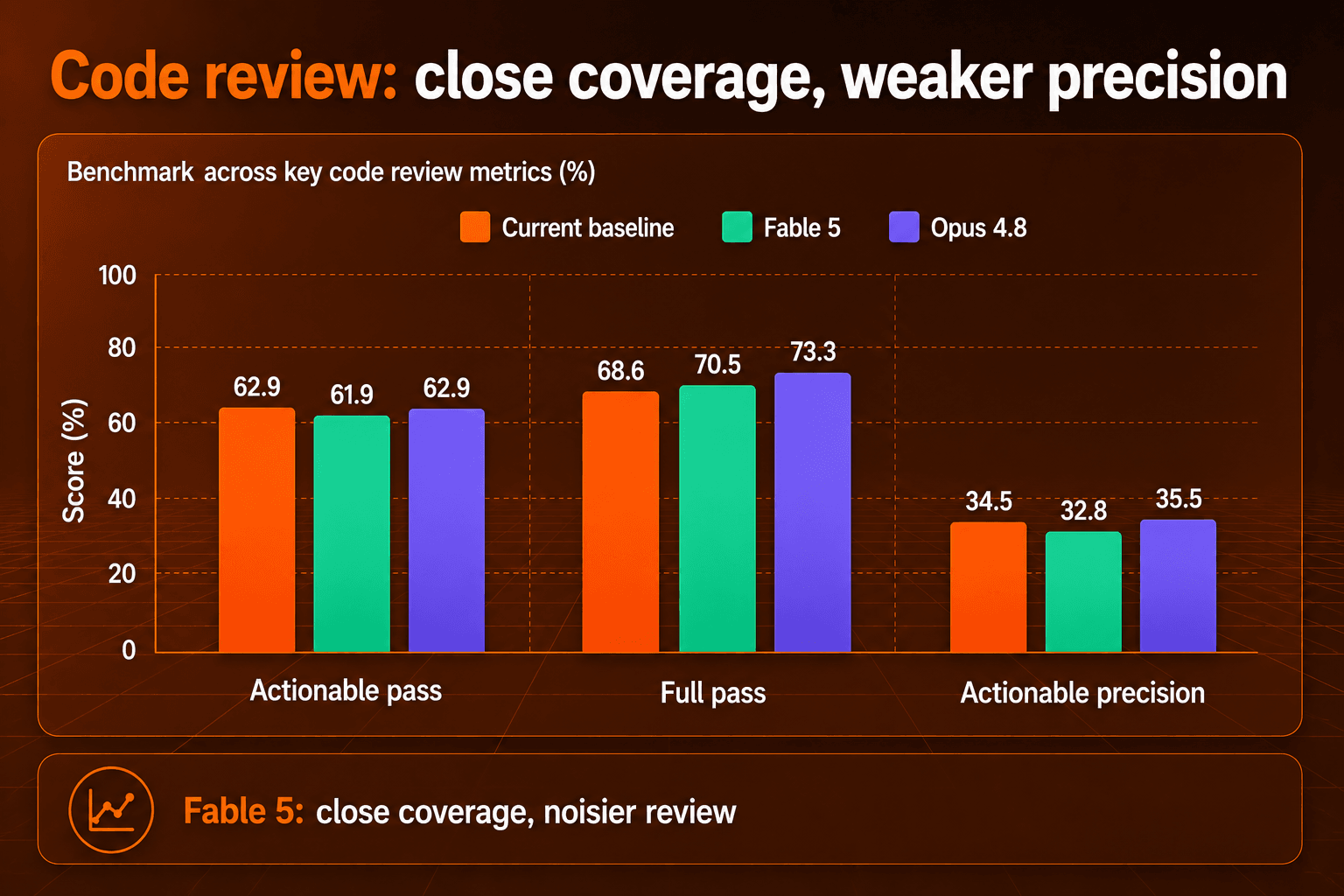
카테고리별로 쪼개 보면 헤드라인 커버리지 수치가 시사하는 것보다 결과가 더 들쭉날쭉하게 느껴집니다. Fable 5는 폭넓게 잘 잡지만 개발자가 리뷰어에게 기대하는 이슈 유형 전반에서 성과가 고르지는 않습니다. 실무에서는 도움이 되는 발견 사항을 기대하되 리뷰 신뢰를 얻기 어려운 카테고리에는 여전히 수동 분류와 폴백 커버리지가 필요합니다.
더 까다로운 사례들을 보면 롤아웃 판단이 한층 신중해집니다. 난이도 4 EP에서 Fable 5는 16개 중 8개를 통과했는데 베이스라인 10개, Opus 4.8 9개에 뒤집니다. 그렇다고 Fable 5가 형편없는 리뷰어라는 뜻은 아닙니다. 다만 리뷰 신뢰를 얻기 가장 어려운 사례에서는 사람의 판단이 더 많이 필요하다는 의미입니다.
보안: 도움은 되지만 자동 신뢰는 금물
개발자는 Fable 5를 일반적인 코딩 모델보다 보안을 더 의식하는 모델로 체감할 가능성이 큽니다. 위험한 동작 주변에서 신중한 구현을 요구하는 작업이라면 더욱 그렇죠. 그렇다고 곧바로 가져다 쓰는 보안 리뷰어로 취급해도 된다는 뜻은 아닙니다. 실무적인 자세는 보안에 민감한 깊이 있는 코딩 작업에 활용하되 그 발견 사항을 신뢰하기 전까지는 리뷰 기준을 높게 유지하는 것입니다.
가장 강한 보안 신호는 능동적인 구현에서 나왔습니다. 저희 코딩 작업 벤치마크에서 Fable 5는 명확한 목표와 코드를 끝까지 풀어낼 충분한 시간이 주어졌을 때 보안 관련 Bandit 작업을 완료했습니다. Fable 5는 리뷰에서 모든 이슈를 잡아내라고 요구받을 때보다 보안이 구체적인 코딩 작업의 일부일 때 더 유용해 보입니다.
코딩 작업 벤치마크: 유능하지만 오래 걸림
분명한 패턴이 드러난 뒤 저희는 코딩 작업 벤치마크를 일찍 중단했습니다. Fable 5는 의미 있는 진전을 만들어 냈지만 많은 작업이 에이전트 타임아웃에 걸릴 만큼 오래 돌아갔습니다. 그래서 이 섹션은 최종 리더보드 점수가 아니라 경험적 신호로 봐 주세요. 유용한 이야기는 작업이 계속 불어날 때 모델이 실제 코딩 업무에서 어떻게 행동하는가입니다.
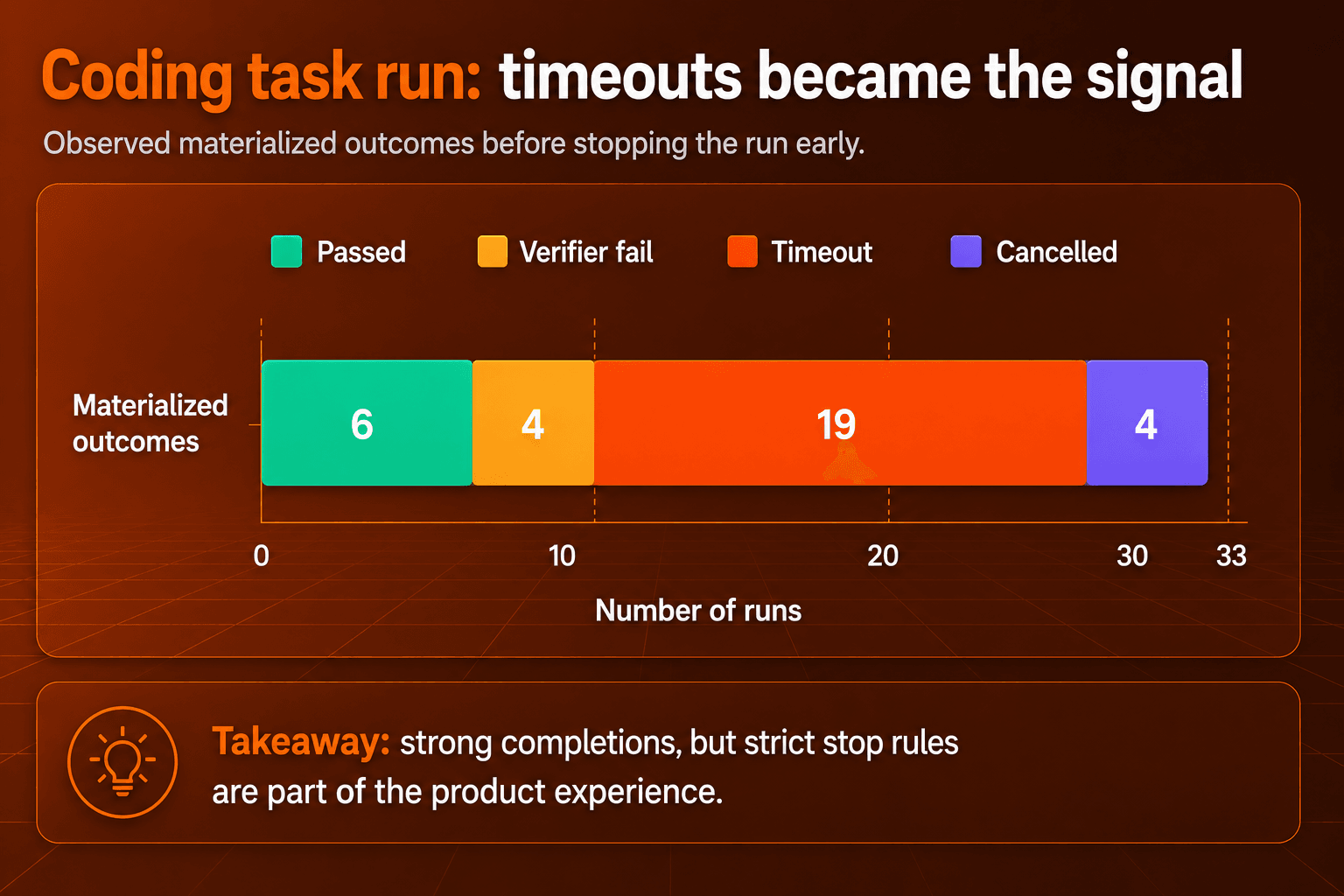
결과 분포는 완료된 벤치마크 점수가 아니라 에이전트 행동에 관한 신호로 읽어야 합니다.
신호는 양쪽으로 작용합니다. Fable 5가 끝까지 갔을 때는 얕은 수정이 아니라 묵직한 패치를 만들어 냈습니다. 반면 막혔을 때는 하니스가 버틸 수 있는 한계를 넘어서까지 탐색을 이어 갔습니다. 개발자에게 이 모델은 기다림을 감수할 만큼 깊이가 가치 있는 작업에 더 잘 맞습니다. 단, 에이전트에 시간, 단계, 토큰에 대한 명확한 한계를 걸어 둔다는 전제가 필요합니다.
완료된 작업들은 Fable 5가 어디서 가장 유용한지도 보여 줍니다. 성공 사례는 타입, API, 퍼블리싱 동작, 쿼리 로직, 캐싱, 보안 관련 코드처럼 실제 구조가 있는 구현 작업에서 나왔습니다. 실패 사례도 유익했습니다. 일부는 빠르게 잘못된 길로 빠진 경우였고 일부는 수렴하지 못한 채 진짜 노력을 쏟아붓는 모습이었습니다. 개발자가 미리 염두에 둬야 할 트레이드오프가 바로 이것입니다. 더 깊지만 항상 깔끔하게 끝나지는 않는다는 점이죠.
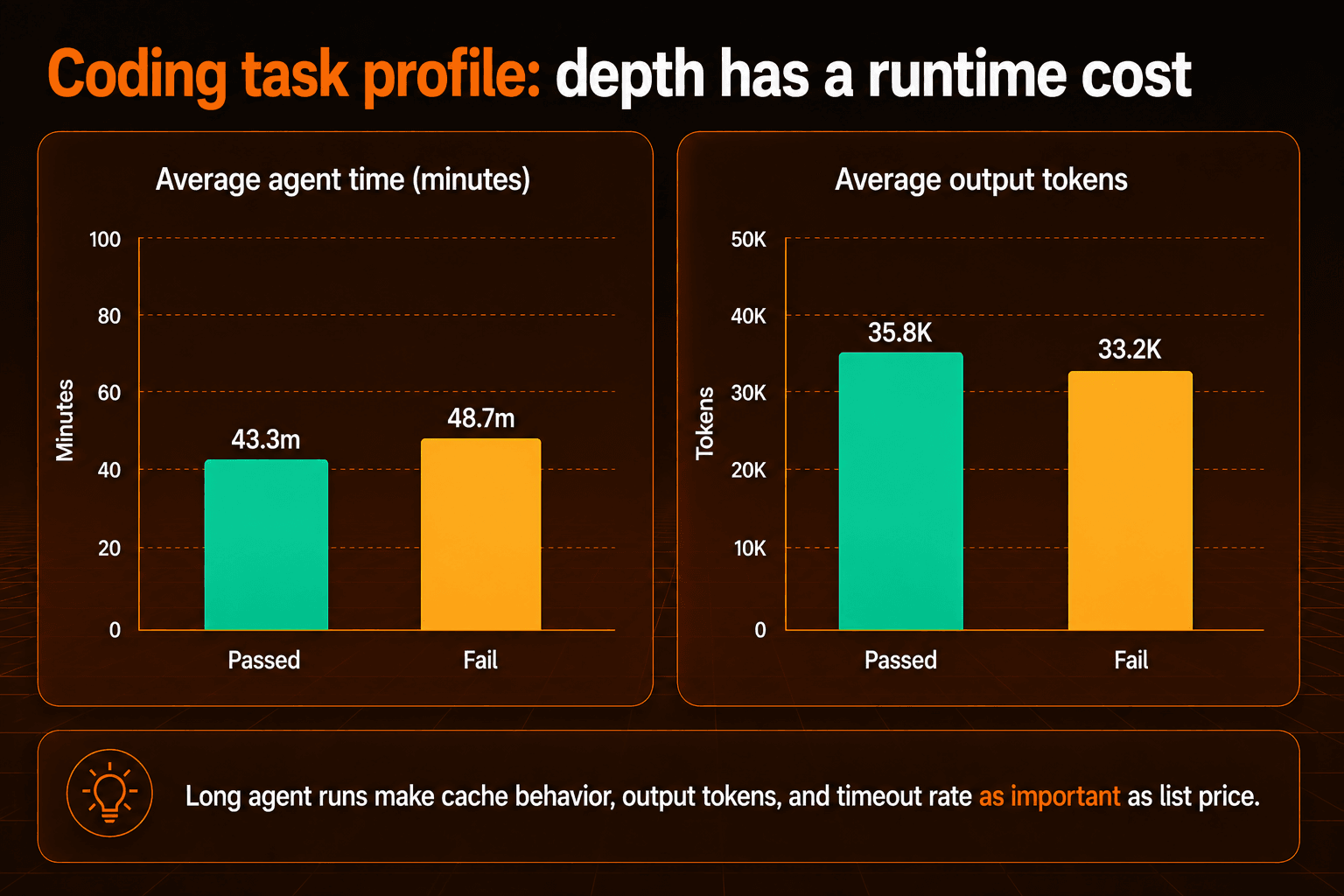
Fable 5는 작업을 끝낼 때 실제 시간과 출력 예산을 적잖이 씁니다. 타임아웃이 나는 경우에도 하니스는 상당한 컨텍스트를 소모할 수 있습니다.
토큰 프로파일은 타이밍 데이터와 같은 이야기를 들려줍니다. Fable 5가 비싼 이유는 정가 때문만이 아닙니다. 답에 도달하기 전에 생각하고 탐색하고 생성하는 데 더 오래 시간을 들이기도 하거든요. 캐시 할인으로 최종 청구액이 줄어들 수 있고 가격도 이후 버전을 거치며 내려갈 수 있겠지만 그래도 모델은 해결한 작업당 비용으로 평가해야 합니다. 이런 부류의 에이전트 작업에서는 타임아웃 비율, 캐시 동작, 출력 토큰 사용량이 공개된 토큰 단가만큼이나 중요합니다.
코딩 프로젝트에서 드러나는 강점
코딩 프로젝트는 Fable 5의 최상의 모습을 가장 선명하게 보여 줬습니다. 한 프로젝트에서 모델은 단순히 동작하는 표면을 짜 맞추는 데 그치지 않았습니다. 상태, 의사결정, 렌더링, 컨트롤을 별도 레이어로 정리한 뒤 빌드를 통과시켰습니다. 남은 빈틈은 첫 완성 버전에서 으레 예상할 만한 종류였습니다. 더 견고한 테스트 커버리지, 더 안전한 상태 처리, 잘못된 입력에 대한 더 엄격한 가드 같은 것들이죠.
또 다른 프로젝트는 더 인터랙티브한 환경에서 같은 패턴을 보여 줬습니다. Fable 5는 안정적인 루프, 절차적 비주얼, 상태를 가진 인터랙션, 페이즈 전환, 캔버스 이펙트, 여러 앱 상태, 성공적인 프로덕션 빌드를 갖춘 실시간 애플리케이션을 만들어 냈습니다. 문제는 기본적인 완성도 실패가 아니었습니다. 결정론적 테스트, 작은 화면 대응, 상태 엣지 케이스처럼 다음 단계의 엔지니어링 작업이었습니다.
이것이 기존 모델 리뷰들과 가장 뚜렷하게 갈리는 질적 차이입니다. 컨텍스트가 충분하면 Fable 5는 계획을 과하게 설명하거나 권한을 거듭 묻는 대신 곧장 구현으로 들어갑니다. 또한 더 좁은 코드 완성용 모델보다 아키텍처, 인터랙션, 제품의 형태에 더 많은 공을 들이는 듯합니다.
권장 사항: Fable 5를 선별적으로 쓰기
권장 사항은 선별적 도입입니다. Fable 5는 자율 코딩 작업에서 테스트해 볼 가치가 있습니다. 특히 더 깊은 계획, 여러 파일에 걸친 실행, 구현에 추가로 들이는 시간에서 이득을 보는 작업이라면 그렇습니다. 다만 프로덕션 코드 리뷰의 기본값으로 삼기에는 아직 이릅니다.
제가 쓸 만한 곳
- 목표가 명확한 자율 코딩 프로젝트.
- 기다림을 감수할 만큼 깊이가 가치 있는 여러 파일 구현.
- 시간, 단계, 토큰 예산이 명시된 에이전트 워크플로.
제가 보류할 곳
- 정밀도 튜닝 전의 기본 코드 리뷰 트래픽.
- 보안 특화 증거가 더 강해지기 전의 보안 리뷰 포지셔닝.
- 긴 실행이 비용이나 지연 리스크를 만드는 고처리량 워크플로.
코드 리뷰라면 Fable 5가 정밀도와 코멘트 양에서 개선될 때까지 현재 베이스라인이나 Opus 4.8 경로를 기본값으로 유지하세요. 코딩 에이전트 쪽에서는 Fable 5가 더 매력적입니다. 탐색과 깊은 구현에서 이득을 보는 작업이라면 특히 그렇죠. 가드레일은 운영 차원입니다. 명확한 예산, 정지 조건, 리뷰 체크포인트를 함께 걸어 두세요. 보안 워크플로에서는 더 나은 보안 리뷰의 증거가 아니라 보안에 민감한 구현에 유용한 도구로 자리매김하는 편이 맞습니다.
같은 맥락에서 다른 모델 비교가 궁금하시다면 Claude Opus 4.7이 AI 코드 리뷰에서 의미하는 것과 Opus 4.8 벤치마크 결과를 함께 보시기를 추천 드립니다. AI 에이전트를 어디까지 믿어야 하는지에 대한 관점은 AI 에이전트를 신뢰하시나요에서 확인하실 수 있습니다.