
Opus 4.8 벤치마크 결과: AI 코드 리뷰와 코드 생성에서의 성능
해당 블로그는 Juan Pablo Flores, Gowtham Kishore Vijay 원저자의 글 'Opus 4.8 Benchmark Results for AI Code Review and Code Generation'을 번역한 것입니다. 더 나은 이해를 위해서 약간의 의역이 반영되었습니다.
새로운 프론티어 모델이 나올 때마다 저희가 묻는 질문은 단순합니다. "실제 코드 리뷰 현장에서 이 모델은 얼마나 더 나아졌는가?" Anthropic이 Claude Opus 4.8을 공개하자마자 저희는 모델 카드의 마케팅 문구 대신, CodeRabbit이 모델 릴리스마다 돌리는 동일한 평가 프레임워크에 곧바로 투입했습니다.
결과부터 말씀드리면, Opus 4.8은 합격률에서 의미 있는 향상을 보였지만 비용은 가파르게 올랐고 컨텍스트가 길어질수록 성능이 떨어지는 익숙한 약점도 그대로 남아 있었습니다. 자세한 수치와 함께, 직접 Opus 4.8을 쓰시려는 분들을 위한 실무 권장 사항을 정리합니다.
Opus 4.8의 새로워진 점
Anthropic은 Opus 4.8에서 세 가지 큰 개선을 발표했습니다.
-
장기 에이전트 실행(Long-horizon agentic execution). 여러 시간에 걸쳐 수많은 도구 호출이 이어지는 세션에서도 모델이 흐트러지지 않습니다. 단, 완전한 스펙을 처음부터 한 번에 주는 경우에 가장 잘 동작하며 요구사항을 중간중간 추가하면 결과가 오히려 나빠집니다.
-
세션 중간의 system 프롬프트(Mid-session system prompts). 메시지 배열에 system 역할 항목을 대화 중간에 추가해도 프롬프트 캐시가 깨지지 않습니다. 다만 모델은 이를 절대적 지시보다는 맥락적 가이드로 해석하며 계획과 불확실성을 더 많이 내레이션하는 경향이 함께 강해졌습니다.
-
도구 사용 재조정(Tool-use recalibration). 웹 검색은 더 자주, 더 적은 반복으로 활성화됩니다. 반면 검색(retrieval) 도구와 메모리 파일은 호출 빈도가 줄었습니다. 결과적으로 고정밀·저재현율(high-precision, low-recall) 동작이 디폴트가 되며 명시적인 지시로 조정할 수 있습니다.
저희가 테스트한 방식
평가에는 모든 모델 릴리스에 동일하게 적용해 온 프레임워크를 그대로 썼습니다. 3단계 복잡도(trivial, minor, major)에 걸친 100개의 오픈소스 PR입니다. 비교는 두 가지 설정으로 진행했습니다. 디폴트(escalating thinking levels)와 사고 수준을 낮춘 변형(reduced-thinking variant)을 CodeRabbit의 현재 프로덕션 앙상블과 동일한 PR 위에서 정면으로 붙였습니다.
측정한 핵심 지표는 두 가지입니다.
- 합격률(Pass rate): 시니어 인간 리뷰어와 동등한 수준의 발견을 모델이 짚어낸 PR의 비율.
- 정밀도(Precision): 시니어 평가자가 실행 가능(actionable)이라고 판정한 코멘트의 비율(잡음 대비).
결과
Opus 4.8 디폴트 설정의 결과는 다음과 같습니다.
- 풀 시스템 합격률: 72% (베이스라인 68%, +4%p)
- 실행 가능(actionable) 합격률: 61% (베이스라인 62%, 통계적 잡음 범위 안)
- 정밀도: 실행 가능 코멘트 기준 33.8%, 풀 시스템 기준 +1%p
"특별히 최적화된 적 없는 표면 위에서, 잘 튜닝된 앙상블과 정면으로 붙어 이 정도면 강한 결과입니다."
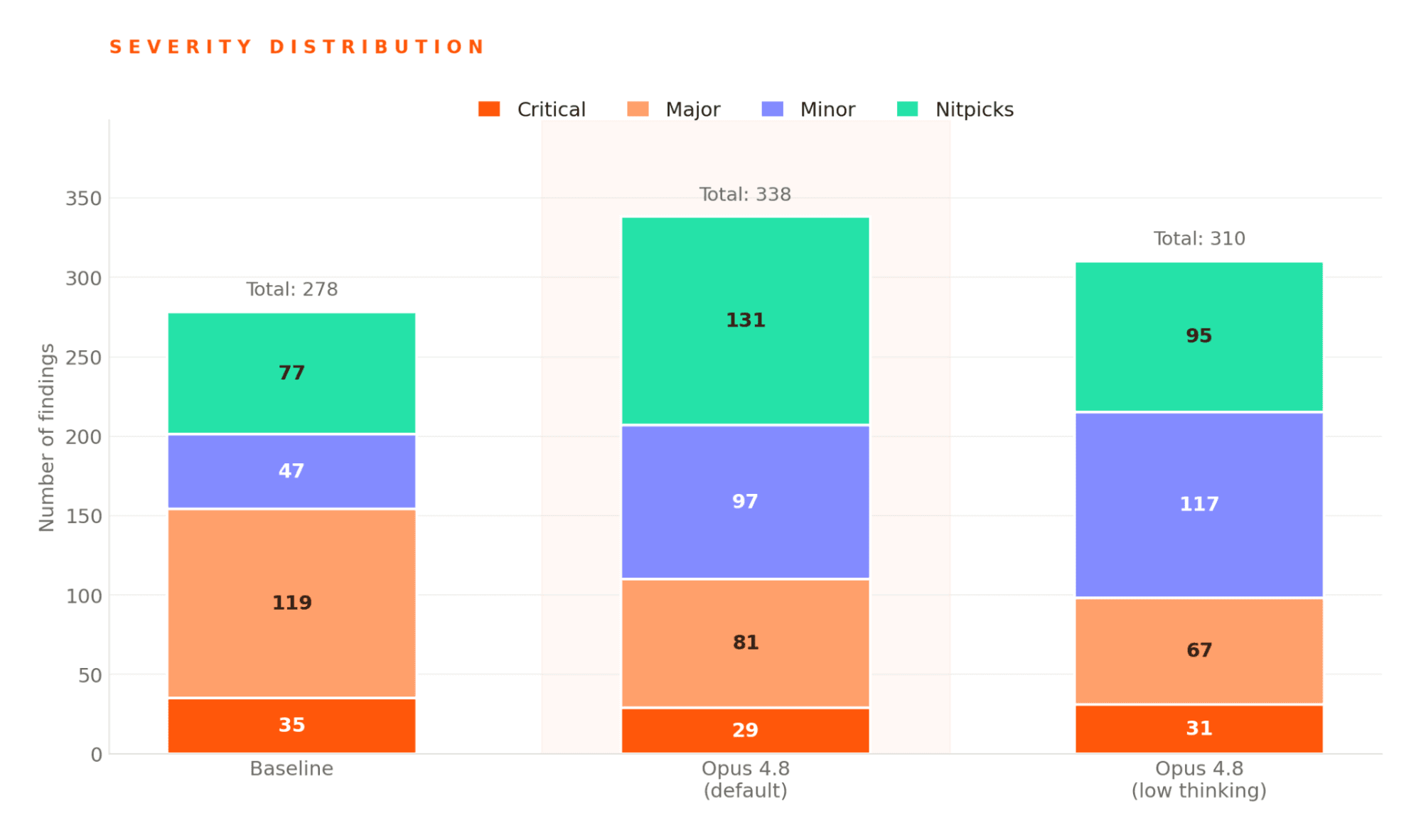
심각도 분포에서는 눈에 띄는 변화가 있었습니다. major 발견이 119건에서 81건으로 줄어든 대신 minor와 nitpick은 거의 두 배로 늘었습니다. 코드 리뷰에서 가장 중요한 critical 발견은 35건에서 29건으로 감소했는데 놓친 critical 이슈는 다른 등급보다 훨씬 큰 비용을 만든다는 점에서 우려스러운 흐름입니다.

비용 측면. 호출당 비용은 $0.20~$0.28 수준으로, Opus 4.5의 $0.13, Sonnet 4.5의 $0.04~$0.12와 비교하면 부담이 큽니다. 리뷰 전용 용도에서는 이 프리미엄을 정당화하기 쉽지 않습니다.
사고 수준의 영향. 추론 노력(reasoning effort)을 낮춘 변형은 정밀도가 4%p, 실행 가능 합격률이 5%p 떨어졌습니다. 즉, 사고 수준 설정은 그냥 다이얼이 아니라 결정적인 튜닝 포인트입니다.
어디서 약했는가
200k 토큰을 넘어가면 성능 저하가 눈에 띄게 시작됩니다. 모델이 느려지고 더 짧은 컨텍스트에서는 깔끔하게 처리하던 참조와 엣지 케이스를 놓치기 시작합니다. 통제된 측정값이라기보다는 핸즈온 관찰에서 나온 결론이지만 Opus 4.8을 직접 쓰는 팀이 모노레포나 대형 코드베이스에서 마주칠 가장 큰 벽이 바로 이 지점입니다.
CodeRabbit 사용자 입장에서의 의미
CodeRabbit은 Opus 4.8을 선별적으로 배치하고 있습니다. 모델의 강점인 파일 간 추론과 계획 수립이 가장 잘 드러나는 시니어 티어 PR에 주로 라우팅하고 trivial·junior 티어 변경은 비용 최적화된 다른 모델이 계속 담당합니다. 에이전트 기능에는 Opus 4.8이 가장 강한 백본으로 들어갈 것으로 보고 있습니다.
Opus 4.8을 직접 쓰시는 분들께
- 사고 수준은 "high"에서 시작하세요. "x-high"가 아니라 high에서 출발해 복잡도 단계별로 어떻게 변화하는지 살펴보세요.
- 장기 작업에는 컨텍스트를 한 번에 주세요. 작업 명세를 처음에 완결된 형태로 제공할 때 성능이 가장 좋습니다.
- 리서치 중심 작업에는 검색 우선·위임 지시를 명시하세요. 디폴트 동작이 고정밀·저재현율 쪽으로 기울어 있으므로, 필요하면 "search first" 같은 지시로 끌어올려야 합니다.
- 제한적인 리뷰 언어 대신 다운스트림 필터링으로 옮기세요. 모델에 "이러이러한 코멘트는 달지 마"라고 묶기보다, 일단 산출물을 받고 뒤에서 거르는 편이 결과가 좋습니다.
- 모델이 독립적으로 내려도 되는 결정을 미리 정의해 두면 토큰 낭비가 줄고 결과 일관성도 올라갑니다.
Opus 4.8은 모든 자리에서 베이스라인을 압도하는 모델이라기보다, 특정 문맥에서 분명한 강점을 보이는 모델입니다. 합격률은 올랐고 비용은 비싸졌으며 200k를 넘어가면 약해진다는 한계도 분명합니다. 저희가 모델을 앙상블로 운영하는 이유도 같은 맥락입니다. 한 모델에 모든 것을 맡기지 않고 각 모델이 가장 잘하는 자리에 배치합니다.
다른 모델과의 비교가 궁금하시다면 Claude Opus 4.7 벤치마크 결과를 함께 보시기를 추천합니다.