
Gemini 3.1 Pro AI 코드 리뷰 벤치마크 - 더 적은 코멘트, 더 높은 Signal-to-Noise
해당 블로그는 David Loker, Erfan Al-Hossami의 원저자의 글 'Gemini 3.1 Pro for Code-Related Tasks: More Focus, Higher Signal-to-Noise'를 번역한 것입니다. 더 나은 이해를 위해서 약간의 의역이 반영되었습니다.
AI 코드 리뷰에서 "많이 지적하는 것"과 "잘 지적하는 것"은 다릅니다. 코멘트가 많아도 핵심을 놓치면 의미가 없고, 코멘트가 적어도 정확하다면 오히려 리뷰 효율이 올라갑니다. CodeRabbit이 Gemini 3.1 Pro의 코드 리뷰 성능을 자체 벤치마크로 평가한 결과, 흥미로운 트레이드오프가 드러났습니다.
핵심을 한 줄로 요약하면 이렇습니다.
"Gemini는 더 적고 집중도 높은 코멘트를 남기며 Signal-to-Noise ratio가 높지만, 전체적으로 탐지하는 버그 수는 더 적다."
벤치마크 방법론

평가에는 실제 GitHub PR에 알려진 에러 패턴을 주입한 내부 데이터셋을 사용했습니다. 각 패턴에는 정답(ground-truth) 이슈 설명이 포함되어 있으며, 리뷰 코멘트가 근본 원인을 직접 지적하거나 실행 가능한 가이드와 함께 리스크를 식별하면 "통과(PASS)"로 판정됩니다.
벤치마크의 구체적인 범위는 다음과 같습니다.
- 25개의 난이도 높은 PR, 각각 알려진 에러 패턴이 삽입됨
- 평가 지표: actionable 코멘트 수, EP(Error Pattern) PASS율, precision, signal-to-noise ratio
- 비교 대상: Gemini 3.1 Pro vs. CodeRabbit Production baseline
- 톤 분류: GPT-5.1을 활용한 자동 분류
성능 결과
Coverage와 Precision
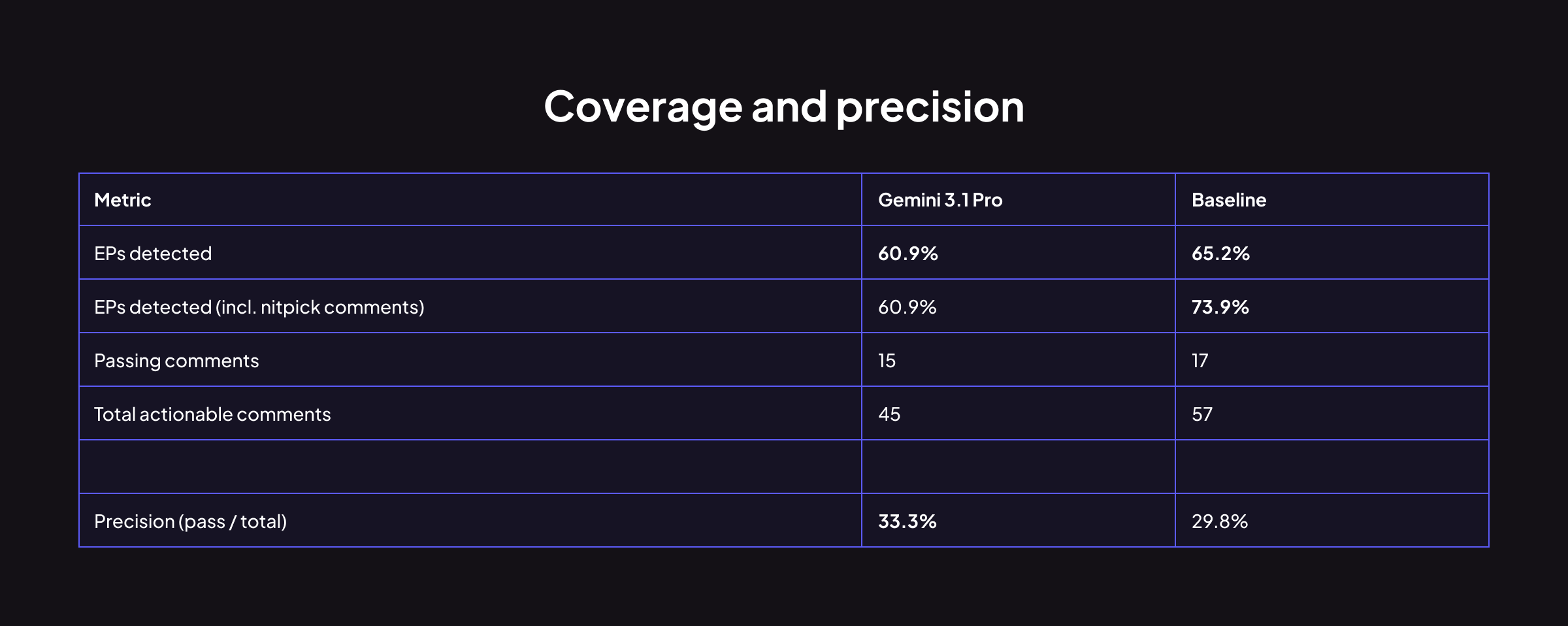
Gemini는 coverage에서 baseline 대비 4.3 percentage point 뒤처집니다. Actionable 코멘트를 24% 적게 생성하는 대신, precision은 약간 더 높습니다(33.3% vs 29.8%). Baseline은 nitpick 수준의 코멘트를 통해 2개의 추가 에러 패턴을 탐지했지만, Gemini는 그러지 못했습니다.
쉽게 말해, Gemini는 "확신이 있을 때만 말하는" 스타일이라 정확도는 높지만, 사소한 단서에서 문제를 잡아내는 능력은 baseline에 비해 부족합니다.
Signal 품질
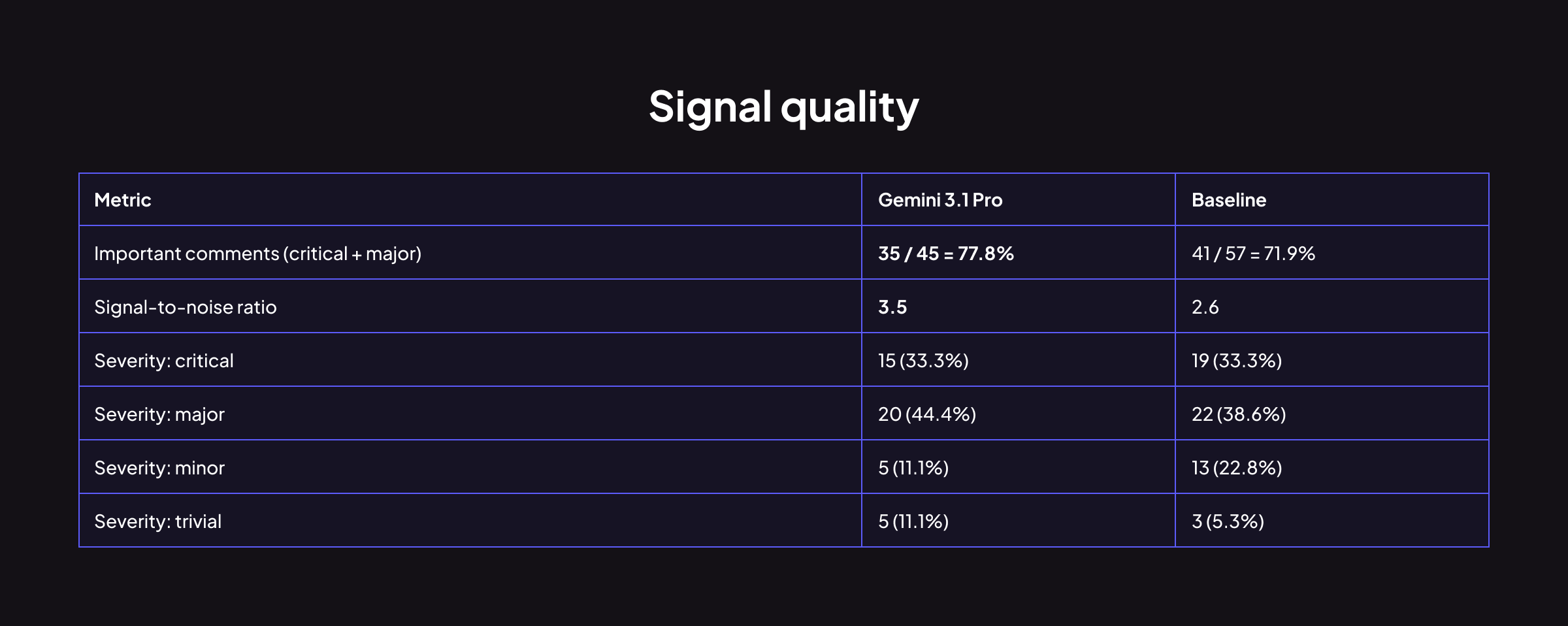
Gemini는 중요 코멘트 비율이 더 높고(77.8% vs 71.9%), signal-to-noise ratio도 우월합니다(3.5 vs 2.6). 전체 코멘트 중 사소한 지적이 차지하는 비중이 상대적으로 적다는 뜻입니다.
개발자 입장에서 이것은 꽤 중요한 차이입니다. 리뷰 코멘트를 하나하나 읽어야 하는 상황에서, 노이즈가 적다는 건 리뷰에 소요되는 인지적 부담이 줄어든다는 의미입니다.
행동 분석: Gemini는 어떻게 코멘트하는가?
톤 프로파일
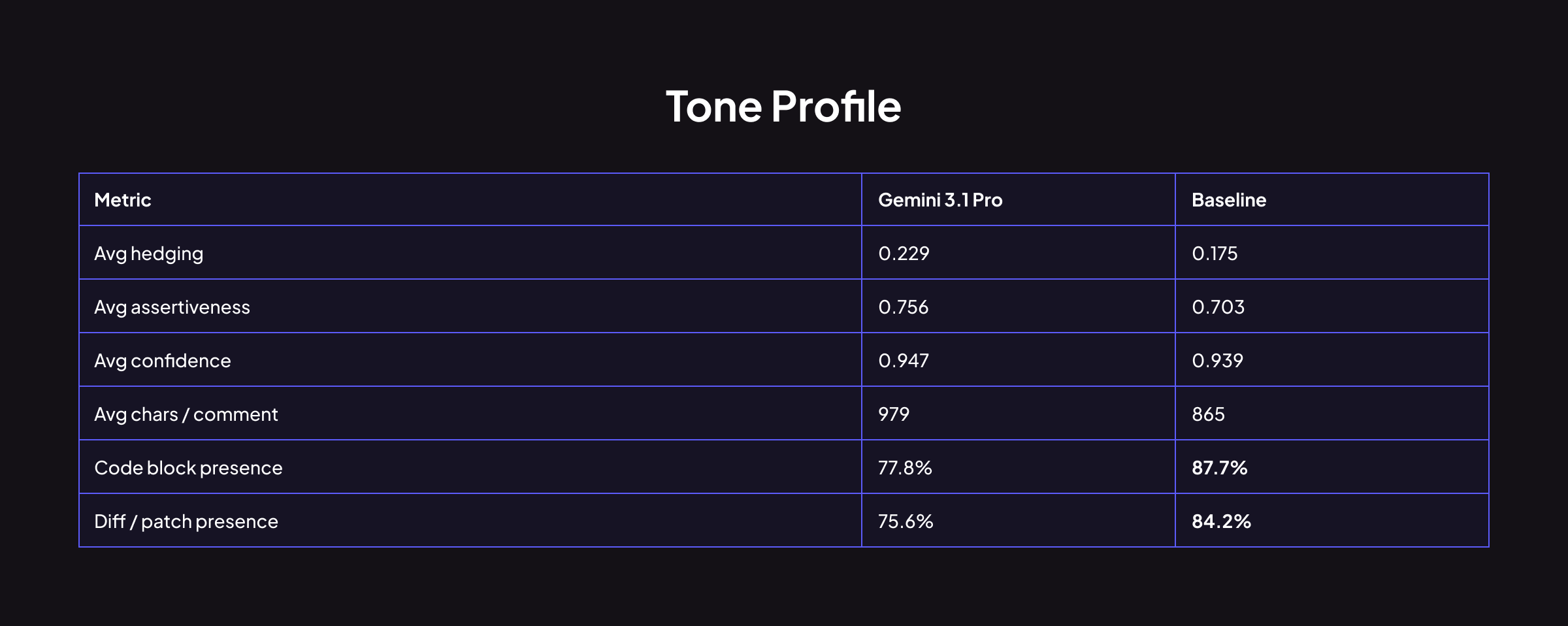
흥미로운 점은 Gemini가 hedging(완곡한 표현)을 더 많이 사용하면서도(0.229 vs 0.175), 동시에 assertiveness(단정적 표현)와 confidence(자신감)도 더 높다는 것입니다(assertiveness: 0.756 vs 0.703, confidence: 0.947 vs 0.939).
코멘트의 평균 길이는 더 길지만, 코드 블록은 baseline보다 적게 포함합니다. 즉, Gemini는 설명 위주로 길게 쓰되, 코드 예시는 절제하는 경향을 보입니다.
핵심 발견: Gemini는 자기가 맞을 때를 안다
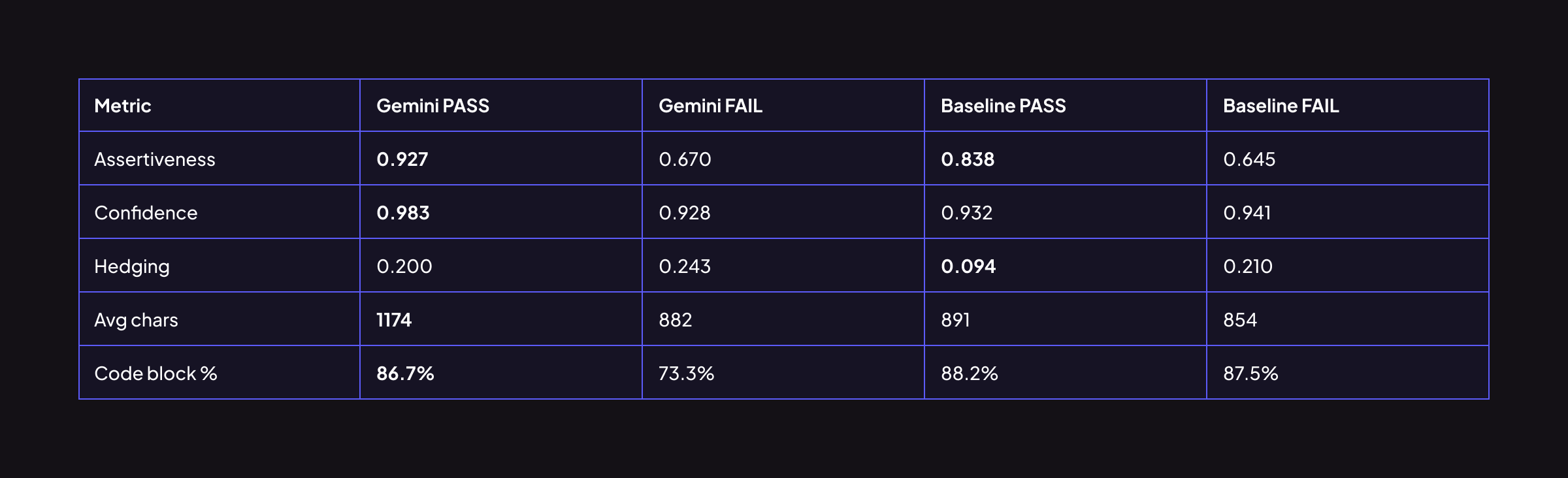
가장 눈에 띄는 발견은 이것입니다.
"Gemini의 통과(PASS) 코멘트는 실패(FAIL) 코멘트보다 assertiveness가 38% 높고, 길이는 33% 더 길다."
다시 말해, Gemini는 정답을 맞혔을 때 더 단정적이고 상세하게 설명합니다. 이 내부 캘리브레이션은 상당히 신뢰할 수 있으며, 높은 assertiveness가 정확도와 상관관계를 보인다는 뜻입니다. 리뷰어 입장에서는 Gemini가 강하게 주장하는 코멘트일수록 주의 깊게 볼 가치가 있다는 실용적인 시사점을 줍니다.
Gemini가 강한 영역

두 모델 모두 탐지에 성공한 이슈에서, Gemini의 통과 코멘트는 평균 1,174자로 baseline의 891자 대비 32% 더 깁니다. 단순히 길기만 한 것이 아니라, 근본 원인(root cause)에 더 집중하는 경향을 보입니다.
버그를 찾았을 때 "이건 문제가 될 수 있습니다"로 끝내는 것이 아니라, 왜 문제인지, 어떤 상황에서 발현되는지를 더 상세하게 설명한다는 것입니다. 코드 리뷰의 교육적 가치 측면에서 의미 있는 차이입니다.
Gemini가 약한 영역: 동시성과 스레딩

Gemini의 가장 뚜렷한 약점은 동시성(concurrency) 관련 버그 탐지입니다.
- Gemini: 9개 에러 패턴 중 5개 탐지 (56%)
- Baseline: 9개 에러 패턴 중 7개 탐지 (78%)
22 percentage point의 격차입니다. Lock 오용, race condition, 타이밍 의존성 등 동시성 관련 패턴에서 Gemini가 일관되게 뒤처지며, 이것이 전체 coverage 차이의 주요 원인입니다.
동시성 버그가 많은 코드베이스(멀티스레드 서버, 비동기 파이프라인 등)를 다루는 팀이라면 이 약점을 반드시 인지해야 합니다. 동시성을 비롯한 사람 vs AI 코드 리뷰의 강점, 약점을 종합적으로 비교한 글은 AI 코드 리뷰 vs 사람 코드 리뷰에서 확인하실 수 있습니다.
결론 및 한계
Gemini 3.1 Pro는 더 높은 품질의, 집중도 높은 코멘트를 생성하며 signal-to-noise ratio에서 우위를 보입니다. 하지만 에러 패턴 탐지율이 60.9%로 baseline의 65.2%에 미치지 못하며, 특히 동시성 관련 버그에서의 약점은 실제 서비스 환경에서 치명적일 수 있습니다.
중요한 주의사항: 이번 벤치마크는 25개 패턴 중 9개(36%)가 동시성 버그로, 동시성 영역에 가중치가 편향되어 있습니다. OOP 설계 오류, 트랜잭션 시맨틱 오류 등 다른 카테고리에서는 Gemini의 성능이 달라질 수 있습니다.
평가는 2026년 2월 24일에 수행되었으며, PASS/FAIL 판정은 독립적인 LLM 심판(judge)이 담당했습니다.
다른 모델 비교가 궁금하시다면
이번 벤치마크는 Gemini 3.1 Pro의 코드 리뷰 특성에 집중했지만, AI 코드 리뷰 도구를 고를 때는 모델별 비교가 함께 필요합니다. 같은 방법론으로 측정한 다른 모델들의 결과를 함께 보시는 것을 추천 드립니다.
- Claude Opus 4.7이 AI 코드 리뷰에서 의미하는 것: 100개 실제 PR로 측정한 Anthropic 최신 모델의 강점.
- OpenAI GPT-5.5 벤치마크 결과: 더 직설적인 커뮤니케이션과 좁고 정확한 코드 변경에서의 강점.
- 2026년 AI 코드 리뷰 툴 Top 10 벤치마크: 200,000개 PR을 분석한 Martian의 독립 벤치마크와 코드 리뷰 도구 순위.
AI 코드 리뷰가 어떤 모델을 쓰느냐에 따라 어떻게 달라지는지 직접 확인해 보고 싶다면, CodeRabbit에서 무료로 시작해 보세요.