
OpenAI GPT-5.5에서 무엇이 달라졌나: 더 나은 판단력, 더 강한 코딩, 더 또렷한 신호
해당 블로그는 Juan Pablo Flores, Abhilash Harish Srivathsa 원저자의 글 'What Changed in OpenAI GPT-5.5: Better Judgment, Stronger Coding, Better Signal'을 번역한 것입니다. 더 나은 이해를 위해서 약간의 의역이 반영되었습니다.
저희의 초기 테스트에 따르면, 이 모델은 더 직설적으로 커뮤니케이션하고, 더 신호가 강한 이슈를 찾아내며, 실무 코딩, 리뷰 워크플로에서 더 좋은 성능을 보였습니다.
참고: 이 모델은 ChatGPT와 Codex에서 GPT-5.5로 사용해 볼 수 있습니다.
GPT-5.5를 사용해 본 느낌은 꽤나 구체적인 방식으로 달랐습니다. 더 빠르고, 더 군더더기가 없고, 더 직설적이었거든요. 실무 관점에서 이는 더 짧은 응답, 더 선택적인 리뷰 행동, 그리고 광범위한 재작성 대신 작고 실행 가능한 변경 쪽으로 더 강하게 기우는 경향으로 이어졌습니다.
모델은 빠르게 응답했고, 오버헤드가 줄어든 형태로 커뮤니케이션했으며, 큰 낭비 없이 실무 답으로 향해 움직였습니다. 그 속도의 일부는 모델이 내부 작업을 다 끝낸 뒤에야 답하지 않고, 사용자에게 보일 진행 상황을 빠르게 노출하는 방식에서도 나타났습니다.
이러한 직설성은 출력의 품질로도 이어졌습니다. 코드 리뷰, 버그 수정, 디버깅 작업 전반에서 모델은 일관되게 범위가 좁혀진(scoped) 변경에 무게를 두었고, 동작을 보존하는 빈도가 더 높았으며, 대체로 추측성 재설계로 흘러가지 않고 실제 실패 모드(failure mode) 에 집중했습니다.
GPT-5.5 코드 리뷰 성능
저희의 테스트에서 가장 또렷하게 드러난 강점 중 하나는 코드 리뷰였습니다. 잘 풀린 사례에서 모델은 구체적이고, 실행 가능하며, 개발자의 흐름을 끊고 알릴 가치가 있는 버그에 집중했습니다.
이 특성은 디버깅 지향 리뷰에서 명확하게 드러났습니다. 작업이 접근 제어, 에러 처리, API 동작과 관련된 경우, 모델은 종종 실제 회귀(regression)를 분리해 내고, 약한 진단을 거부하며, 의도된 동작을 보존하는 수정안을 제시할 수 있었습니다.
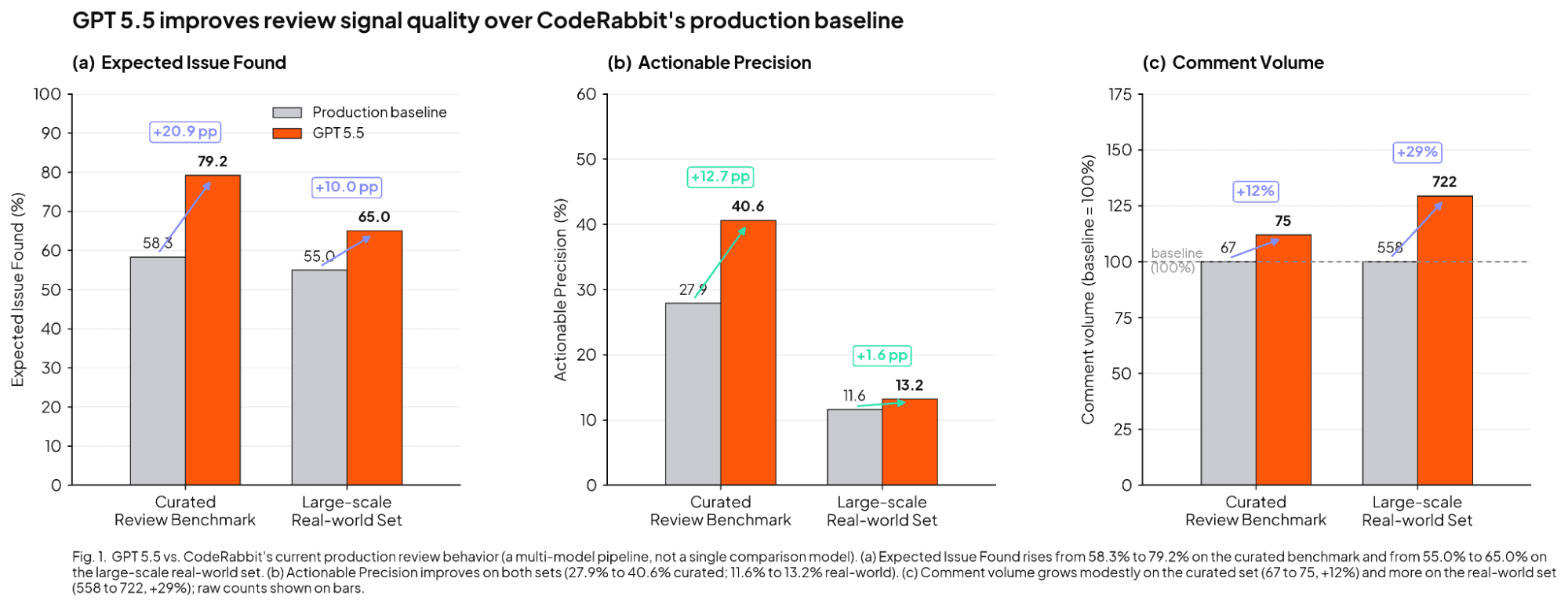
벤치마크 결과도 이 관찰과 일치합니다. 아래 다이어그램과 본문에서 언급되는 "베이스라인(baseline)"은 단일 비교 모델을 가리키지 않습니다. 그것은 CodeRabbit의 현재 라이브 리뷰 시스템을 의미하며, 단일 모델이 아니라 여러 모델의 조합으로 동작합니다.
저희의 GPT-5.5 초기 테스트에서, 에이전트는 큐레이션된 리뷰 벤치마크에서 기대 이슈 발견율(Expected Issue Found) 을 베이스라인 대비 58.3%에서 79.2% 로 끌어올렸고, 정밀도(precision)는 27.9%에서 40.6% 로 향상시켰으며, 코멘트는 베이스라인 67건 대비 75건을 생성했습니다. 즉, 코멘트 양은 약간만 늘리면서도 유용한 이슈를 훨씬 더 많이 찾아낸 셈입니다.
대규모 실세계 리뷰 세트에서도 GPT-5.5는 여러 핵심 지표 전반에서 성능이 향상되었습니다. 구체적으로, 기대 이슈 발견율은 베이스라인 55.0%에서 65.0% 로 상승했고, 정밀도는 11.6%에서 13.2% 로 개선되었습니다. 다만 이 세트에서는 에이전트가 더 수다스러워져, 이전 베이스라인의 558건 대비 722건의 코멘트를 생성했습니다.
실무적 정리는 이렇습니다. GPT-5.5는 신호 품질에서 베이스라인을 능가했습니다. 다만 리뷰 양 자체가 베이스라인보다 일관되게 적었던 것은 아닙니다.
이 동작의 일부는 프롬프트 뒤에 있는 리뷰 표준(review standard) 에서 나오는 것으로 보입니다. 단순히 말하면, 모델은 현재 변경에 국한된, 구체적이며, 작성자가 직접 고칠 수 있을 만큼 명확한 진짜 버그만 표시하도록 유도되고 있습니다.
숨겨진 의도를 추측하거나, 코드베이스 전반의 품질을 두루뭉술하게 트집 잡거나, 컴파일러, 타입 체커, 린터가 이미 잡아낼 만한 이슈를 표시하는 일은 하지 않도록 되어 있습니다. 코멘트 가이드도 동일한 논리를 따릅니다. 간결하게, 명시적으로, 사실 위주로 적도록 합니다.
이 성능이 향후 롤아웃까지 이어진다면, CodeRabbit 사용자에게 체감 가능한 이점이 됩니다. 선택성이 높아진다는 것은 무관한 코멘트를 솎아내는 데 들어가는 시간이 줄고, 중복 리뷰 스레드가 줄어들며, 받은 피드백이 정말로 다뤄야 할 이슈를 가리킬 가능성이 더 커진다는 의미입니다.
GPT-5.5 코딩 성능
리뷰와 별개로, 모델은 코드 생성과 구현 작업에서도 우수했습니다. 이 영역의 주된 강점은 통제력(control) 이었습니다. 모델은 범위를 좁힌 변경을 선택하고, 요청이 있을 때는 기존 인터페이스를 보존하며, 과잉 구현을 피하는 경향이 있었습니다.
수집된 사례들에서 그 패턴이 분명히 드러났습니다. 엔드포인트 확장, 라우트 컨트랙트 유지, 운영 이슈 해결 같은 작업에서 모델은 일관되게 예측 가능한 결과를 내는 정밀한 수정안을 선호했습니다. 안전성을 강화하고, 인터페이스를 보존하며, 의도치 않은 부작용을 최소화하는 방향이었죠. 코드를 통째로 다시 쓰는 대신, 주변 시스템의 안정성을 유지하면서 이슈를 해결할 수 있는 가장 작은 수정을 우선시했습니다.
GPT-5.5의 코드 생성은 작업이 구체적이고 범위가 한정되어 있을 때 빛납니다. 버그 수정, 작은 API 조정, 기존 동작을 유지하는 리팩토링, 타깃을 명확히 한 테스트 추가 같은 포커스된 작업에 매우 효과적입니다.
UI 작업에서도 같은 패턴이 드러났습니다. 매끈한 인터랙션 작업과 견실한 라이브러리 사용을 보여줬지만, 독창성은 실행 품질만큼 높지는 않았습니다. 저희 팀이 본 것은 기대 이상의 애니메이션 처리와 비범하게 디테일한 인터랙션이었지만, 동시에 익숙한 스타일 선택으로 회귀하는 경향(특히 눈에 띄는 인디고-바이올렛 컬러 편향)도 있었습니다.
GPT-5.5는 명확한 지시와 가장 잘 맞습니다
모델을 직접 사용하는 개발자에게 인터랙션 패턴은 꽤 분명합니다. 모델은 작업이 범위가 명확하고, 제약 조건이 명시적이며, 환경이 피드백을 줄 수 있을 때 가장 잘 동작하는 것으로 보입니다. 즉, 구체적인 요구 사항을 주고, 인터페이스 기대치를 보존하게 하며, 가능한 한 시스템을 직접 실행하거나 점검하도록 두는 것이 좋습니다.
모델은 한 번에 모든 것을 풀려 하기보다, 변경 → 점검 → 보정의 가시적인 루프를 거칠 수 있을 때 더 좋은 결과를 냈습니다. 이는 테스트 전반에서 본 더 큰 패턴과도 부합합니다. 더 직설적인 출력, 토큰 낭비의 감소, 그리고 경계가 명확한(bounded) 작업에서 더 나은 결과.
저희 팀의 테스트에서는 모델이 지시를 너무 글자 그대로 따르는 경향도 드러났습니다. 특히 프롬프트가 잘 구조화되어 있지 않거나, 디테일이 부족하거나, 근본 개념이 약할 때 그랬습니다. 이런 경우 모델은 스스로 방향을 교정하지 않는 경우가 많았습니다. 더 노련한 협업자라면 잠시 멈추거나, 명확화를 요청하거나, 전제를 도전했을 법한 상황에서도, 요청된 그대로 실행하는 경향이 있었습니다.
이는 곧, 프롬프트 품질이 결과에 미치는 영향이 개발자가 예상하는 것보다 더 크다는 의미입니다. 모델은 의도된 동작, 제약 조건, 성공 기준이 구체적인 요청에서 가장 강해 보입니다.
모호하거나 내부적으로 일관되지 않은 프롬프트는 빠른 응답을 이끌어 낼 수 있지만, 그 출력은 프롬프트가 가진 약점을 교정하기보다 거울처럼 비추어 낼 가능성이 큽니다.
장시간 동작하는 에이전트를 위한 토큰 절감
GPT-5.5의 주목할 만한 포커스 중 하나는 효율성입니다. 이는 리뷰 성능보다 벤치마크로 측정하기 어렵지만, 저희 테스트에서 가장 뚜렷이 드러난 트렌드 중 하나였습니다. 모델은 종종 덜 장황했고, 보이는 진행 상황을 빠르게 노출했습니다. 이는 새 버전이 동등한 작업을 이전 모델보다 더 적은 토큰으로 처리할 수 있음을 시사합니다. 하나의 벤치마크 수치로 분리해 내기는 어려운 종류의 이점이죠.
이는 반복 시도를 거듭해 정답에 수렴해야 하는 에이전트 하니스(harness) 에 특히 의미가 있습니다. OpenClaw류 패턴을 따르는 시스템이나, 에이전트가 계획, 실행, 점검, 재시도, 정련을 수많은 사이클에 걸쳐 수행해야 하는 모든 워크플로에서, 토큰 비효율은 빠르게 복리로 누적됩니다.
모델이 효과적인 동시에 간결함을 유지할 수 있다면, 이런 긴 루프에서의 토큰 무거운 오버헤드를 줄일 수 있습니다. 외부 서비스나 에이전트 플랫폼 위에서 빌드하는 팀에게 이는 토큰 사용량이 워크플로의 발목을 잡기 전까지 더 많은 반복 여유를 의미합니다.

GPT-5.5을 써야 할까요?
GPT-5.5의 주된 강점은 개발자 워크플로에 있습니다. 구체적으로 다음 영역에서 두드러집니다.
- 이전 모델보다 실질적인 이슈를 더 많이 식별
- 광범위한 리팩토링 없이 포커스된 변경 구현
- 초기 오류 이후의 효과적인 자기 교정(self-correction)
CodeRabbit 같은 도구를 평가하는 팀에게 가장 방어 가능한 주장은 "리뷰당 신호 품질이 베이스라인보다 좋아졌다" 이지, "리뷰 양이 보편적으로 줄었다" 가 아닙니다. 모델을 직접 사용하는 개발자에게 패턴은 똑같이 분명합니다. 범위가 명확한 작업을 주고, 제약 조건을 명시하고, 모델이 실제 시스템을 통해 자신의 작업을 검증하게 두십시오.
다른 모델과의 비교가 궁금하시다면 Claude Opus 4.7 AI 코드 리뷰 벤치마크와 Gemini 3.1 Pro 코드 리뷰 벤치마크를, 200,000개 PR을 분석한 독립 벤치마크는 Code Review Bench v0에서 확인하실 수 있습니다.