
Nemotron 3 Ultra: 빠르고 열린 코딩 모델의 가능성
해당 블로그는 Juan Pablo Flores, Basem Rizk 원저자의 글 'Nemotron 3 Ultra makes the case for fast, open coding models'을 번역한 것입니다. 더 나은 이해를 위해서 약간의 의역이 반영되었습니다.

코드 리뷰 모델을 고를 때 저희가 가장 먼저 보는 건 정확도입니다. 그에 못지않게 중요한 게 속도이기도 하죠. 모델이 느리면 명령만 던져 놓고 다른 일을 하러 가게 되거든요. 반대로 빠르면 화면 앞에 머물면서 후속 질문을 던지고 여러 번 시도하고 에이전트 하니스(harness)가 계속 밀어붙이도록 둘 수 있습니다. NVIDIA의 Nemotron 3 Ultra는 바로 그 "빠르고 열린(open) 코딩 모델"이라는 지점을 정면으로 겨냥한 모델입니다.
Nemotron 3 Ultra에 대해 알려진 것
Nemotron 3 Ultra는 NVIDIA Nemotron 3 제품군에서 가장 큰 모델입니다. 이 제품군은 Nano, Super, Ultra로 구성되며 모두 에이전트형 AI 애플리케이션을 염두에 두고 설계됐습니다. 그중 Ultra는 라인업의 대형 추론 엔진에 해당합니다. 전체 파라미터가 약 5,500억 개이며 희소 전문가 혼합(sparse mixture-of-experts) 설계를 통해 토큰당 약 550억 개가 활성화됩니다.
가장 깔끔한 비교 대상은 제품군의 직전 대형 모델인 Nemotron 3 Super입니다.
| 특성 | Nemotron 3 Super | Nemotron 3 Ultra |
|---|---|---|
| 제품군 내 역할 | 에이전트 워크플로용 고처리량 추론 모델 | 더 복잡한 코딩, 리서치, 엔터프라이즈 워크플로를 위한 최대 추론 모델 |
| 전체 파라미터 | 1,200억 | 5,500억 |
| 활성 파라미터 | 토큰당 120억 활성 | 토큰당 550억 활성 |
| 아키텍처 | 하이브리드 Mamba-Transformer MoE | 하이브리드 Mamba-Transformer MoE |
| 전문가 설계 | Latent MoE | Latent MoE |
| 컨텍스트 길이 | 최대 100만 토큰 | 최대 100만 토큰 |
| 효율 기능 | Multi-token prediction과 NVFP4 학습/배포 경로 | Multi-token prediction과 NVFP4 지향 배포 경로 |
| 적합한 용도 | 대량 에이전트 워크플로, 코딩, 기획, 도구 사용 | 속도, 규모, 더 강한 추론이 한 루프 안에 함께 있어야 하는 까다로운 개발 워크플로 |

좀 더 풀어 보면, 단순히 더 큰 밀집(dense) Transformer가 아닙니다. Ultra는 토큰마다 네트워크의 일부만 활성화하고 긴 컨텍스트를 실용적으로 유지하며 토큰을 빠르게 생성하도록 만들어졌습니다. 느린 백그라운드 배치 작업처럼 다루지 않고 대화하듯 인터랙티브하게 쓸 수 있을 만큼요.
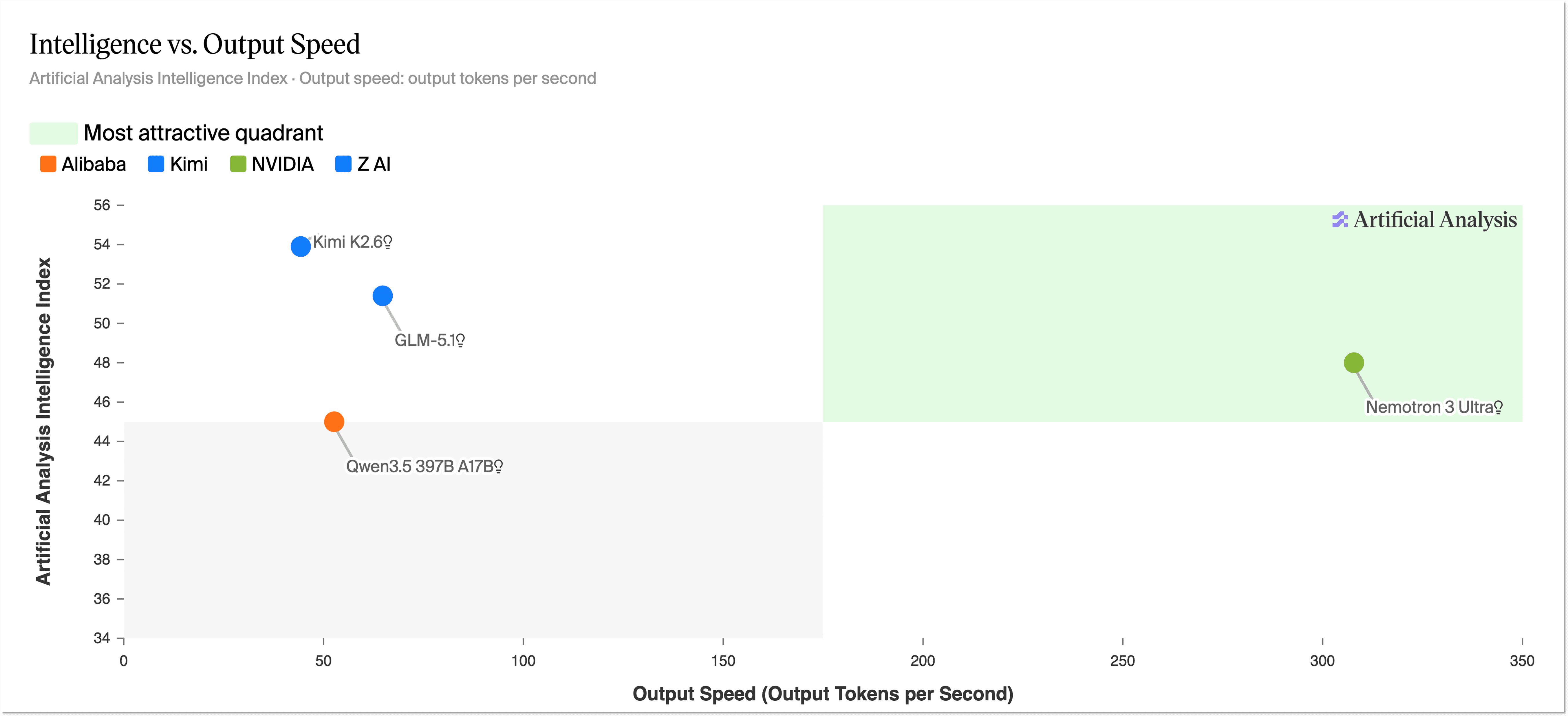
출시와 함께 공개된 수치는 Ultra를 꽤 좋은 위치에 올려놓습니다. Artificial Analysis는 Nemotron 3 Ultra의 Intelligence Index를 48로 보고했습니다. 해당 시점 기준 미국산 오픈 웨이트(open-weight) 모델 중 1위입니다. Gemma 4 31B, Nemotron 3 Super, gpt-oss-120b를 앞섰습니다. Kimi K2.6이 54로 여전히 더 높기 때문에 Ultra가 오픈 프론티어 전체를 장악했다는 이야기는 아닙니다. 핵심은 도달한 지능 수준 대비 속도가 유난히 빠르다는 점입니다.
Artificial Analysis는 출시 전 DeepInfra 엔드포인트에서 초당 300토큰이 넘는 출력 속도도 보고했습니다. 개발자 입장에서는 이 속도가 진짜 쓸모 있는 부분이죠. 코딩에서는 지연 시간이 행동을 바꿉니다. 모델이 느리면 명령을 던지고 잊어버리게 됩니다. 빠르면 루프 안에 머물면서 후속 질문을 던지고 여러 번 시도하고 에이전트 하니스가 계속 밀어붙이도록 둘 수 있습니다.
이번에 달라진 점
Nemotron 3 Super는 이미 NVIDIA가 에이전트 워크플로에 쓸 만한 오픈 모델을 만들 수 있다는 사실을 보여줬습니다. Ultra는 여기서 두 가지 방향으로 더 나아갑니다.
첫째, 훨씬 큽니다. Super는 전체 약 1,200억 파라미터에 활성 약 120억 수준입니다. Ultra는 전체 약 5,500억, 활성 약 550억으로 올라갑니다. 이렇게 커진 규모는 NVIDIA와 초기 테스터들이 모델을 설명하는 방식에서 드러납니다. 작고 효율적인 보조 모델이 아니라, 선택된 워크플로에서 독점(proprietary) 프론티어 시스템의 일을 가져오기 시작할 수 있는 모델로 이야기됩니다.
둘째, Ultra는 개발자 하니스를 더 직접적으로 염두에 두고 학습·평가된 것으로 보입니다. NVIDIA는 Super가 결과적으로 에이전트 하니스에서 잘 작동한 모델이었던 반면 Ultra는 처음부터 그런 하니스를 고려해 만들었다고 언급합니다. 코딩 도구 입장에서는 요구 조건이 달라집니다. OpenCode, OpenHands, Kilo Code, Continue, 또는 내부 코드 리뷰 루프에서 잘 동작하는 모델은 단순히 질문에 답하는 것 이상을 해야 합니다. 도구 프로토콜을 따르고 긴 컨텍스트를 관리하고 반복되는 프롬프트 속에서 진전을 만들고 막혔을 때 스스로 회복해야 합니다.
Ultra의 동작은 그 목표에 잘 맞습니다. 빠르고 직설적이며 그다지 장황하지 않고 확인 질문을 많이 던지지 않습니다. 하니스 안에서는 강점이 될 수 있지만 작업이 명시되지 않은 요구 사항에 의존한다면 약점이 되기도 합니다. 명확한 지시를 줄수록 결과가 좋아집니다. 가장 적절한 사고 모델은 Claude식 프롬프팅보다 Codex식 프롬프팅에 가깝습니다. 작업을 또박또박 적어 주세요. 합격 기준(acceptance criteria)을 제시하세요. 기대하는 출력 형식을 명시하세요.
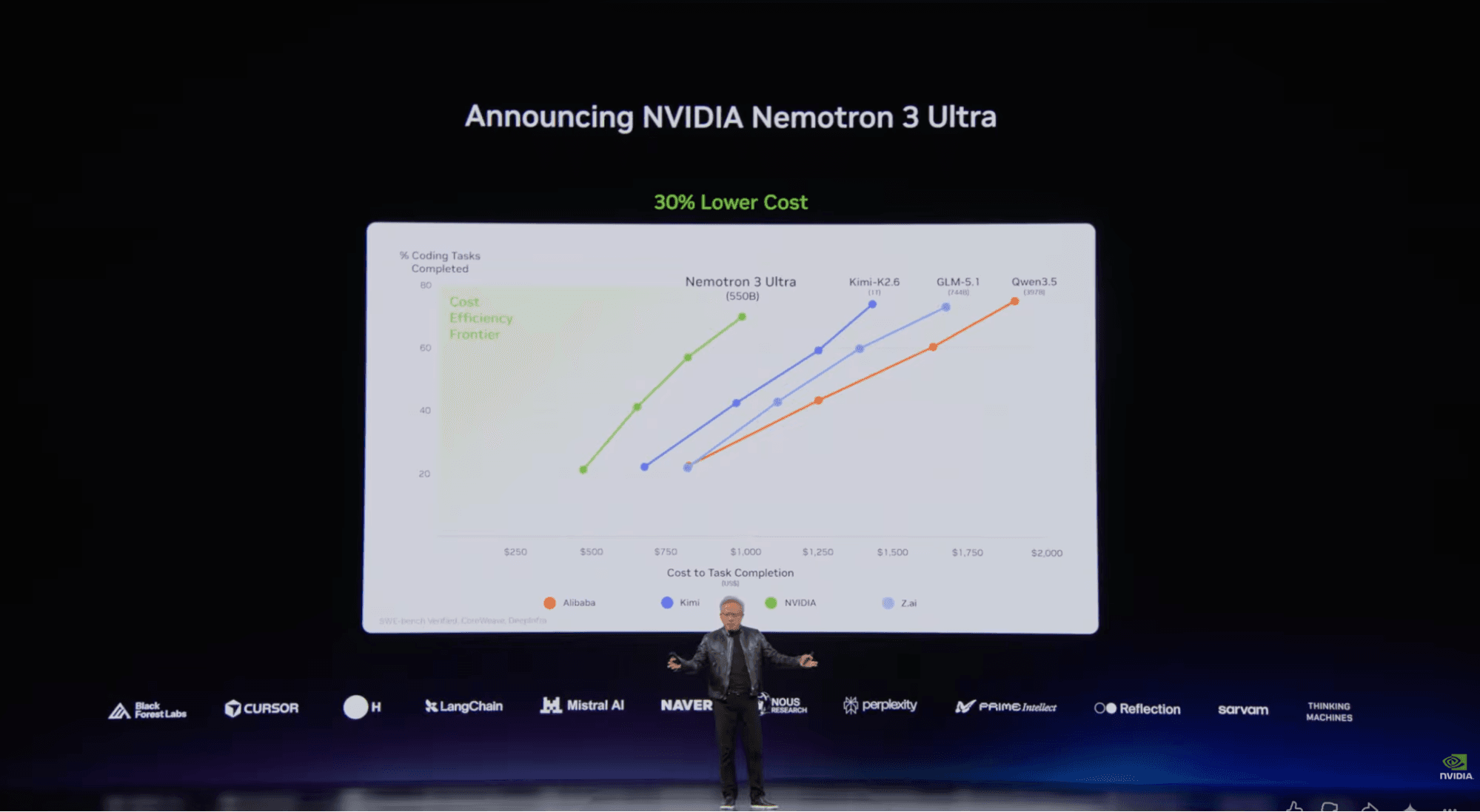
CodeRabbit 벤치마크 성능
CodeRabbit의 내부 벤치마크는 출시 차트만 보는 것보다 현실에 더 가까운 그림을 보여줍니다. 이 벤치마크는 베이스라인 리뷰 모델 묶음과 Nemotron 3 Ultra 구성을 105개의 평가 문제에 걸쳐 비교합니다. 쉬운 이슈부터 어려운 리뷰 작업까지 다양합니다. 평가는 검증, 중복 제거, 단호한 필터링을 거친 파이프라인 이후의 최종 코멘트를 사용합니다. 채점은 gpt-5.1로 진행했으며 중간 추론, 낮은 verbosity, 단일 모드, 3회 투표 조건이었습니다.
상단 결과는 박빙입니다.
- 베이스라인 평균(N=3): 105개 중 60개 통과, 즉 57%
- Nemotron 3 Ultra 평균(N=2): 105개 중 58개 통과, 즉 56%
- 베이스라인 풀 통과: 105개 중 66개, 즉 63%
- Nemotron 3 Ultra 풀 통과: 105개 중 65개, 즉 62%
- 베이스라인 실측 정밀도(precision): 34.0%
- Nemotron 3 Ultra 실측 정밀도: 33.0%
긍정적으로 읽으면, 이 리뷰 워크로드에서 Ultra는 통과 지표상 베이스라인과 거의 같은 구간에 있었습니다. 실제 이슈를 찾아냈고 리뷰 파이프라인을 통과했으며 쓸 만한 CodeRabbit 스타일 코멘트를 만들어 냈습니다.
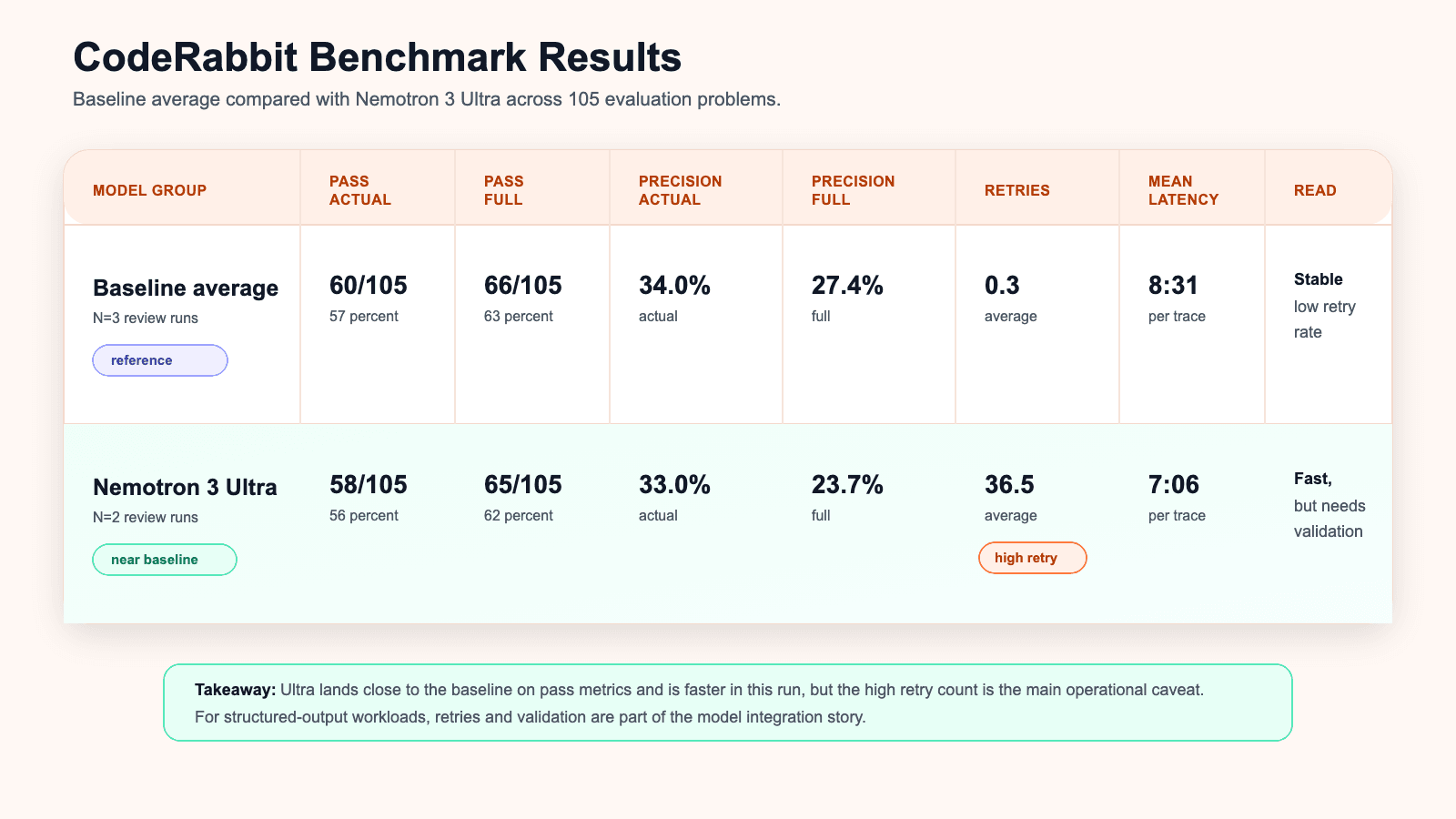
다만 신경 쓰이는 부분은 안정성입니다. 모델의 재시도(retry) 비율이 높았습니다. 벤치마크 요약에 따르면 Ultra 실행의 평균 재시도는 36.5회로 베이스라인의 0.3회와 대비됩니다. 재시도 분포를 보면 약 66%가 스크래치패드(scratchpad)에만 머문 경우였습니다. 실무적으로 말하면, 모델이 가끔 필수 출력 마커나 최종 구조화 출력을 만들기 전에 스스로 멈춰 버립니다. 프롬프트를 바꾸지 않고 다시 시도하면 대체로 잘 됩니다. 능력 자체는 있다는 뜻이지만 첫 시도 완료 동작이 무시해도 될 만큼 안정적이지는 않습니다.
CodeRabbit 데이터에서 끌어낸 실무적 결론은 명확합니다. Nemotron 3 Ultra는 일을 해낼 수 있지만 구조화 출력 작업에서는 검증과 재시도 로직으로 감싸 주어야 합니다.
지연 시간 쪽에도 흥미로운 신호가 있습니다. 벤치마크에서 Ultra 실행은 전체 리뷰 트레이스당 평균 지연 7분 6초를 기록했습니다. 베이스라인의 8분 31초보다 빠릅니다. 이 특정 리포트에서 엄청난 차이는 아니지만 Ultra 실행은 큰 재시도 부담을 안고서도 시간 면에서 경쟁력을 유지했습니다. Ultra에 관한 NVIDIA의 설명은 반복적으로 같은 아이디어로 돌아옵니다. 모델이 충분히 빠르다면, 여러 번의 시도가 한 번의 느리고 신중한 시도를 여전히 이길 수 있다는 것입니다.
비용 이야기는 벤치마크에서 덜 깔끔합니다. 이 특정 표에서 Ultra 실행의 총비용은 베이스라인보다 높게 보고됐습니다. 다만 이 수치는 과하게 일반화하면 안 됩니다. 내부 폴백(fallback) 비율, 호스팅 엔드포인트 가격, 재시도 동작이 로컬 실험을 좌우할 수 있기 때문입니다. NVIDIA와 Artificial Analysis의 공개 서사는 완료까지의 비용(cost-to-completion)과 처리량에 관한 것입니다. CodeRabbit 결과는 그보다 좁은 이야기를 합니다. 이 벤치마크에서 품질은 비슷했고 속도는 경쟁력이 있었으며 안정성 제어 루프는 손을 더 봐야 합니다.
개발자에게 Ultra가 강해 보이는 지점
Nemotron 3 Ultra가 가장 빛을 발하는 쓰임새는 "모든 코딩 모델을 대체하기"가 아닙니다. "명확한 지시와 외부 검증을 곁들여, 쓸모 있는 개발 작업을 빠르게 대량으로 돌리기"입니다.
다음과 같은 용도에서 가능성이 보입니다.
- 코멘트를 검증, 필터링, 중복 제거, 재시도할 수 있는 코드 리뷰 파이프라인
- 통합 테스트 생성, 특히 모델이 넓은 컨텍스트를 읽어야 하는 경우
- 여러 파일이나 문서를 훑어야 하는 레포지토리 리서치 작업
- 하니스가 작업이 끝날 때까지 모델을 계속 움직이게 할 수 있는 에이전트 워크플로
- 완벽한 원샷 추론보다 빠른 반복이 더 도움이 되는 일상 코딩 작업
NVIDIA는 유용한 예시도 공유했습니다. Ultra를 OpenCode에서 사용해 여러 논문을 읽고 그 사이를 가로지르며 추론하게 한 사례입니다. 박사급 코딩 난제는 아니지만 속도가 워크플로를 바꾸는 바로 그런 일상 개발 작업이죠. 터미널에 머무르며 모델이 움직이는 걸 지켜보고 계속 방향을 잡아 줄 수 있습니다.
CodeRabbit 스타일 작업에서는 쉬운 난이도와 중간 난이도의 리뷰 작업에서 특히 흥미로워 보입니다. 이런 리뷰도 충분히 가치 있습니다. 시스템은 실무적인 이슈를 잡아내고 명확히 설명하고 매번 더 비싼 프론티어 모델을 기다리지 않고도 많은 리뷰 출력을 만들어 내야 하니까요.
개발자가 주의할 점
Ultra에는 구조가 필요합니다. 코딩이나 개발 자동화에 쓴다면 자유 형식 채팅 모델처럼 다루면서 알아서 워크플로를 추론해 주길 기대하면 안 됩니다. 하니스를 주세요. 체크리스트를 주세요. 정지 조건을 주세요. 출력 검증을 주세요.
실무 가이드는 이렇습니다.
- 구체적인 합격 기준이 담긴 명확한 프롬프트를 쓰세요.
- 구조화 출력의 경우 응답을 받아들이기 전에 필수 마커나 스키마를 검증하세요.
- 조기 정지에 대비한 재시도 로직을 추가하세요.
- 골 루프(goal loop)나 외부 완료 체크를 써서 작업이 실제로 끝날 때까지 모델이 계속 일하게 하세요.
- 테스트는 명시적으로 요청하세요. 초기 핸즈온에서 모델이 항상 자체 테스트를 생성하지는 않았습니다.
- 디자인 요구 사항은 구체적으로 적으세요. 기대 이상의 시각 산출물을 만들기도 하지만 디자인이 핵심 강점은 아닙니다.
- 여러 번의 시도가 허용되는 고처리량 워크플로에 우선 활용하세요.
- 잘못된 출력 하나가 프로덕션 자동화를 망가뜨릴 수 있는 워크플로에는 신중하세요.
이 모델은 팀이 벤치마킹을 바라보는 방식도 바꿉니다. 순수한 원샷 벤치마크는 실제 제품 루프가 재시도를 허용한다면 Ultra를 과소평가할 수 있습니다. 반대로 재시도를 무시한 벤치마크는 제품이 엄격한 첫 시도 포맷을 요구한다면 Ultra를 과대평가할 수 있습니다. 올바른 지표는 아마 "쓸 만한 완료까지의 시간(time-to-usable-completion)"에 가까울 텐데, 품질, 재시도, 지연, 비용을 함께 측정하는 것입니다.
결론
Nemotron 3 Ultra가 개발자에게 흥미로운 오픈 모델 출시 중 하나인 이유는, 지능만 쫓지 않기 때문입니다. 쓸 만한 처리량을 함께 쫓습니다.
이 모델은 크고 열려 있고 빠릅니다. 공개 벤치마크는 미국산 오픈 웨이트 지능의 상위권에 올려놓으면서 출력 속도에서는 많은 경쟁자를 한참 앞서게 합니다. CodeRabbit의 벤치마크는 좀 더 냉정한 그림을 더합니다. Ultra는 탄탄한 리뷰 베이스라인에 근접한 성능을 낼 수 있지만 구조화 출력 안정성을 위해서는 현재로선 재시도와 외부 검증이 필요합니다.
판단은 단순하지 않습니다. 첫 시도에 모든 엄격한 포맷을 정확히 맞히는 모델을 원한다면 Ultra가 아직 가장 안전한 기본값은 아닙니다. 반면 하니스가 검증하고 재시도하고 작업이 끝날 때까지 모델을 밀어붙일 수 있는 에이전트 개발 시스템을 만든다면 Ultra는 훨씬 매력적인 선택지가 됩니다.
코딩 팀에게 더 큰 이야기는 Nemotron 3 Ultra가 좋아하는 채팅 모델을 대체하느냐가 아닙니다. 열려 있고 고처리량인 코딩 에이전트가 이제 실용적으로 느껴지기 시작하느냐입니다.
관련 글로는 CodeRabbit이 같은 모델을 어떻게 지원하는지 다룬 CodeRabbit의 Nemotron 3 Ultra 지원과, 다른 프론티어 모델 벤치마크를 정리한 Opus 4.8 벤치마크 결과, GPT-5.5 벤치마크 결과를 함께 보시길 추천 드립니다.