#LLM 코드 리뷰
‘LLM 코드 리뷰’ 태그가 달린 글 9개

OpenAI GPT-5.5에서 무엇이 달라졌나: 더 나은 판단력, 더 강한 코딩, 더 또렷한 신호
OpenAI GPT-5.5을 CodeRabbit 리뷰 파이프라인에 투입해 초기 벤치마크를 돌려본 결과를 공유합니다. 더 직설적인 커뮤니케이션, 더 또렷한 신호, 그리고 좁고 정확한 코드 변경에서 강점이 두드러졌습니다.
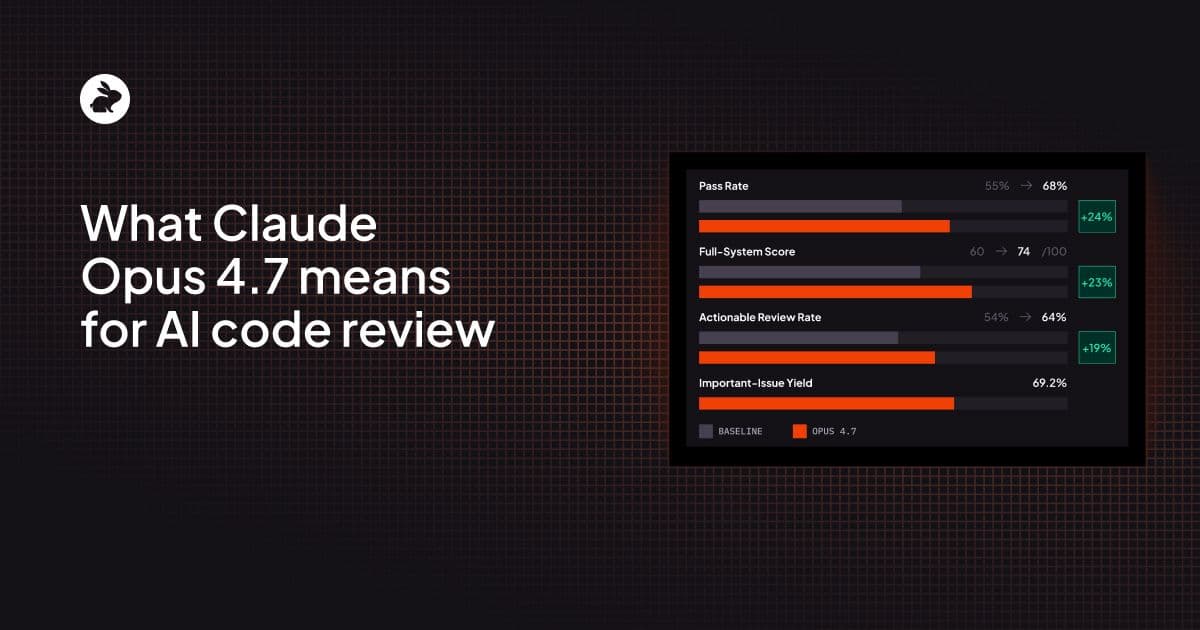
Claude Opus 4.7이 AI 코드 리뷰에서 의미하는 것
Claude Opus 4.7을 CodeRabbit의 프로덕션 리뷰 파이프라인에 투입해 100개의 실제 오픈소스 PR로 벤치마킹한 결과를 공유합니다. 더 많은 버그를 잡고, 더 실행 가능한 피드백을 만들고, 파일 간 추론도 한층 깊어졌습니다.

에이전틱 코드 리뷰 vs RAG: 멀티 리포지토리 분석에서 에이전트가 이기는 이유
RAG 기반 리뷰 도구는 왜 리포지토리 경계를 넘는 변경을 잡아내지 못할까요? CodeRabbit이 2024년부터 에이전틱 아키텍처를 선택한 이유와, 실시간 탐색 방식이 정적 인덱싱보다 우월한 이유를 설명합니다.

AI 코딩의 짧은 역사: Copilot에서 차세대 에이전트까지
Transformer 논문에서 Copilot, 그리고 백그라운드 코딩 에이전트까지. AI가 소프트웨어 개발을 어떻게 바꿔왔는지, 그 흐름을 따라갑니다.

CodeRabbit 멀티 레포 분석: 크로스 레포 장애를 머지 전에 잡아내기
코드레빗 멀티 레포 분석으로 마이크로서비스 환경의 크로스 레포 장애를 머지 전에 자동 감지하세요. AI 코드 리뷰가 연결된 레포지토리 간 영향을 분석해 배포 사고를 예방합니다.

Gemini 3.1 Pro AI 코드 리뷰 벤치마크 - 더 적은 코멘트, 더 높은 Signal-to-Noise
Gemini 3.1 Pro의 AI 코드 리뷰 성능을 코드레빗(CodeRabbit) 파이프라인에서 벤치마크했습니다. 더 적지만 집중도 높은 코멘트, 그리고 동시성 버그 탐지에서 드러난 약점을 다른 LLM 코드 리뷰 모델과 비교 분석합니다.

바이브 코딩 뜻과 의미 변천사 - 트윗 한 줄에서 프로덕션 AI 코드 리뷰까지
바이브 코딩 시대, AI 코드 리뷰는 왜 더 중요한가요? 트윗 한 줄에서 시작된 바이브 코딩이 1년 만에 의미가 역전된 과정과, AI 생성 코드를 검증해야 하는 이유를 정리합니다.
AI 코드 리뷰 vs 사람 코드 리뷰 - 코드리뷰 '조차' 이제 AI가 더 잘하나요?
AI 코드 리뷰 도구는 인간 리뷰를 대체할까요? CodeRabbit 벤치마크로 본 AI의 강점(보안 취약점, 일관성)과 한계(도메인 로직)를 비교합니다. 바이브 코딩 시대 사람과 AI의 역할 분담 가이드.
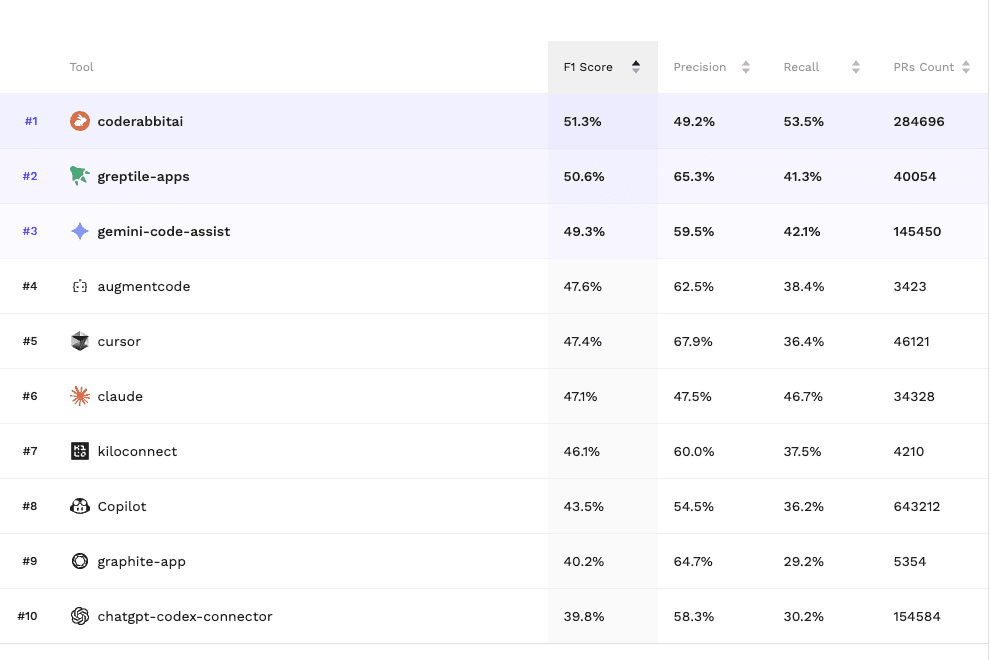
2026년 최고의 AI 코드 리뷰 툴 Top 10 벤치마크
코드레빗(CodeRabbit)이 AI 코드 리뷰 도구 비교 벤치마크에서 F1 Score 1위를 차지했습니다. 200,000개 PR을 분석한 독립 벤치마크로 10개 AI 코드 리뷰 툴 순위를 확인하세요.